
From Monolithic Agents to Composable Workflows: What Microservices Taught Us About Building Reliable AI Agents
If you have spent enough time building backend systems, you have probably lived through the monolith-to-microservices migration at some point in your career. The pain of untangling a giant codebase into smaller, independently deployable services. The learning curve around service contracts, circuit breakers, distributed tracing, and all the operational overhead that comes with it.
Now, looking at how AI agents are being built today, that same pattern is happening again — just in a different domain.
After reading through several discussions and articles on agentic AI architecture (particularly Suleiman Sadiq’s piece on Red Hat’s approach), one thing became clear: agentic AI is a distributed system. And the same engineering principles that made microservices successful — explicit contracts, decomposition, resilience, and observability — apply directly.
This post is my attempt to connect those dots from a backend engineer’s perspective.
Why This Analogy Matters
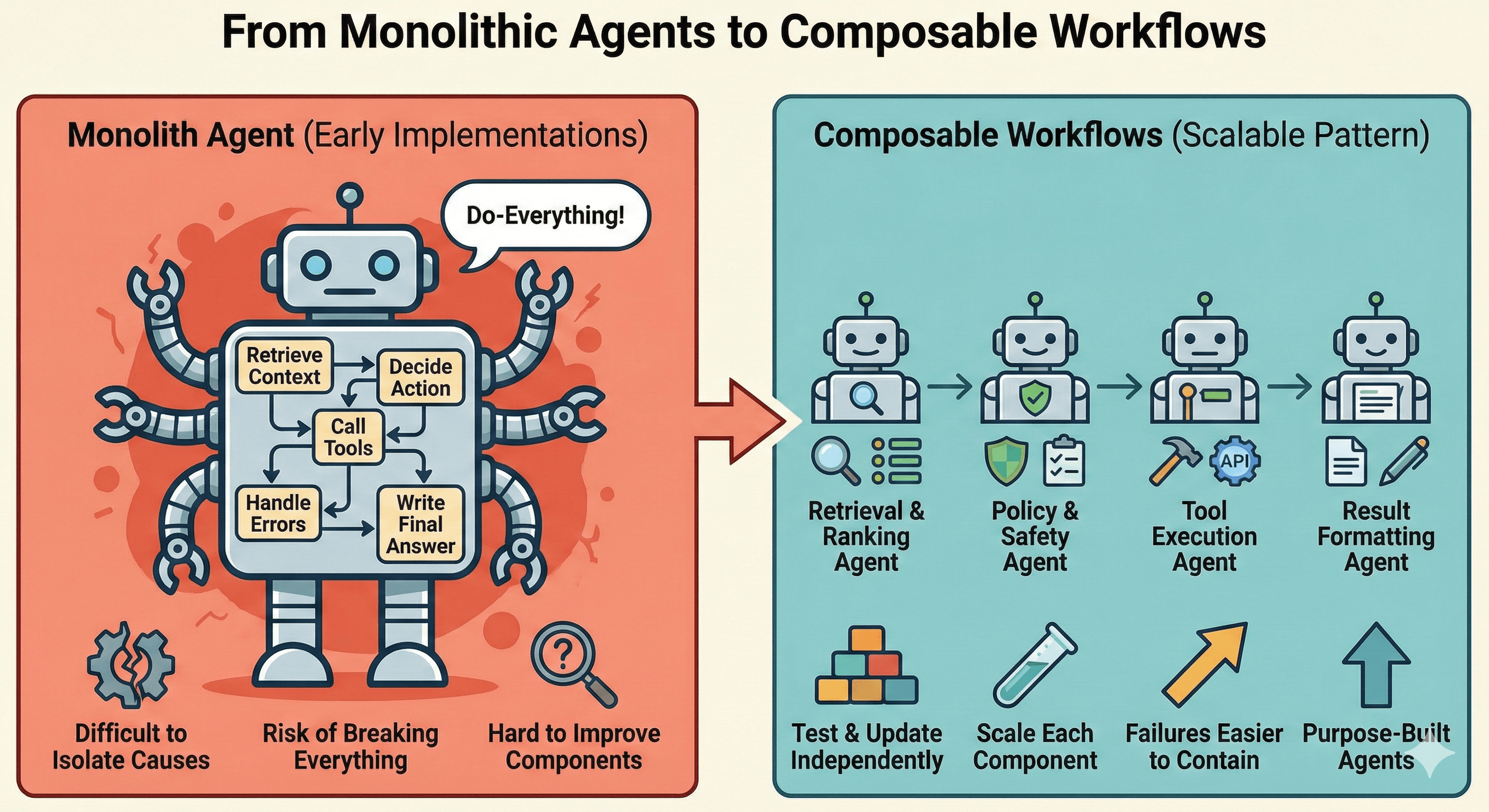
When I first started exploring AI agents beyond simple prompt-response chains, the early implementations felt familiar in an uncomfortable way. A single agent that retrieves context, reasons about what to do, calls tools, handles errors, and produces the final answer. Convenient — but also the AI equivalent of a monolith.
If you have ever maintained a monolithic backend service that does everything — authentication, business logic, data access, notification sending, reporting — you know the pain. When something breaks, isolating the root cause is difficult. When you want to improve one part, you risk breaking everything else. Deployment becomes a high-risk event.
The same problems show up with monolithic agents. And the same solutions apply.
flowchart LR
subgraph monolith["Monolithic Agent"]
direction TB
A["Retrieve Context"]
B["Decide Action"]
C["Call Tools"]
D["Handle Errors"]
E["Format Response"]
A --> B --> C --> D --> E
end
subgraph composable["Composable Workflow"]
direction TB
F["Retrieval Agent"]
G["Validation Agent"]
H["Execution Agent"]
I["Response Agent"]
end
monolith -->|"Decompose"| composable
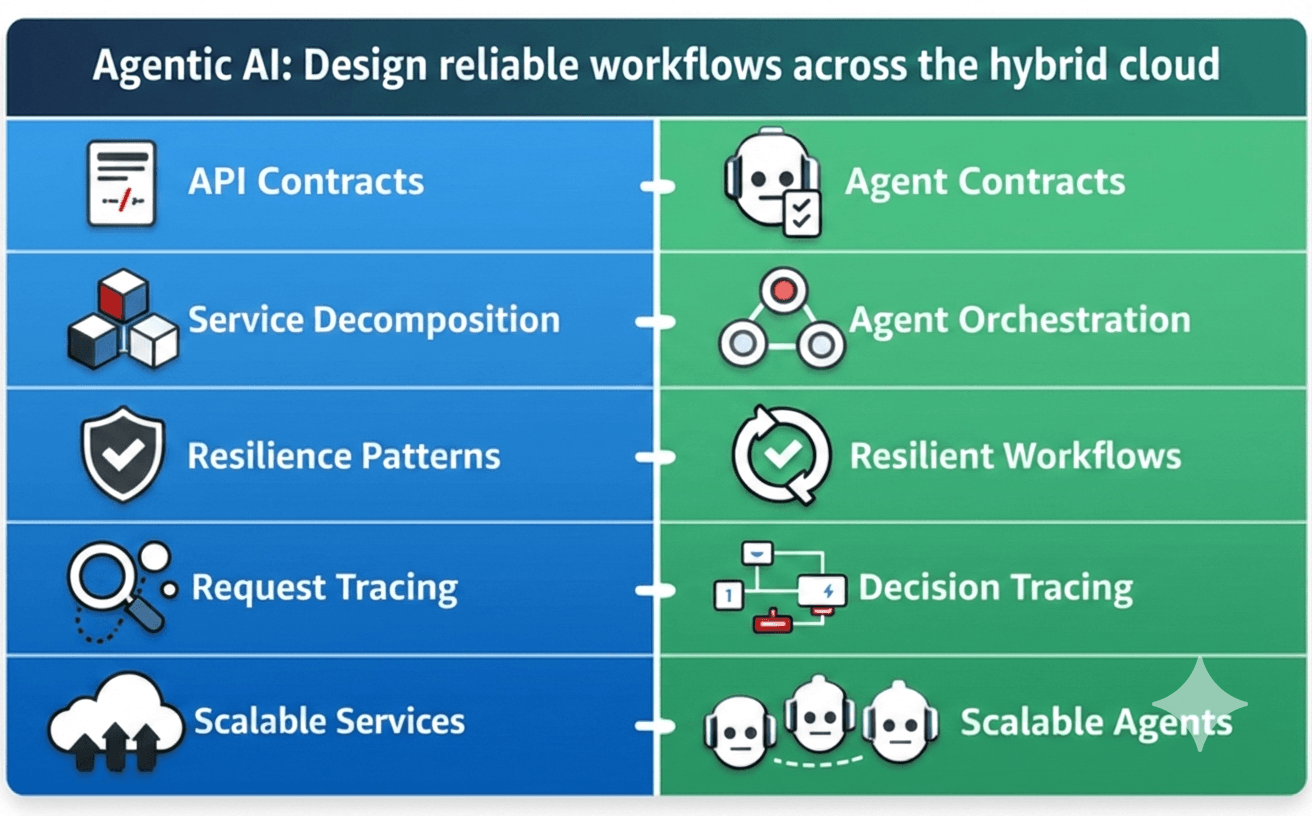
The Microservices-to-Agents Mapping
What makes this analogy practical (not just theoretical) is how directly the patterns map. Here is a comparison that resonated with me:
| Microservices Pattern | Agentic AI Equivalent |
|---|---|
| API contracts (OpenAPI, gRPC) | Structured input/output schemas (JSON Schema) for agents |
| Service decomposition | Breaking one big agent into purpose-built agent pipeline |
| Circuit breakers & retries | Timeouts, fallbacks, and retry logic for tool calls and inference |
| Distributed tracing (Jaeger, Zipkin) | Step-level traces across agent workflow (tool calls, reasoning, retrieval) |
| Independent scaling | Scaling inference, retrieval, and tool execution separately |
| API gateway / service mesh | Orchestrator layer that routes between agents |
| Governance & compliance | Tool allowlists, data access policies, prompt guardrails |
This is not a forced analogy. If you squint, an agent calling a tool over an API is structurally identical to a service calling another service over HTTP. The failure modes are the same: latency spikes, partial failures, versioning mismatches, security boundary violations. The operational concerns are the same: how do you observe it, how do you scale it, how do you roll it back when things go wrong.
From One Big Agent to Composable Workflows
The decomposition principle from microservices is arguably the most impactful pattern when applied to agents.
Instead of one agent that does everything, break the workflow into smaller, purpose-built agents and orchestrate them as a pipeline:
flowchart LR
A["Client Request"] --> B["Orchestrator"]
B --> C["Retrieval Agent
(fetch & rank context)"]
C --> D["Validation Agent
(check policy & safety)"]
D --> E["Execution Agent
(call tools & APIs)"]
E --> F["Response Agent
(format & deliver)"]
F --> G["Client Response"]
Each agent has a single responsibility. You can test, update, and scale each one independently. When retrieval quality drops, you know exactly where to look. When you want to swap out the underlying model for the execution step, you do not risk breaking the validation logic. Failures become contained rather than cascading.
A Concrete Example: Order Processing Agent
To make this less abstract, consider an e-commerce order processing workflow. A monolithic agent approach would look like:
"You are an order processing agent. When a customer asks about their order,
look up the order in the database, check shipping status from the logistics API,
calculate any refund eligibility, and respond with all relevant details.
Handle errors gracefully."That single prompt is doing too much. A composable approach:
flowchart TD
A["Customer Query"] --> B["Intent Agent
'What is the customer asking?'"]
B -->|Order Status| C["Order Lookup Agent
(DB query + caching)"]
B -->|Refund Request| D["Refund Eligibility Agent
(policy rules + calculation)"]
B -->|Shipping Question| E["Logistics Agent
(API call to carrier)"]
C & D & E --> F["Response Composer Agent
(format for channel)"]
F --> G["Customer Response"]
Each agent is testable in isolation. The Intent Agent can be evaluated against a labeled dataset. The Refund Eligibility Agent can be unit tested against policy rules. The Logistics Agent can be mocked during development. This is the same testability advantage microservices gave us over monoliths.
Contracts: Even More Important with Agents
In microservices, teams learned the hard way that services without explicit contracts lead to integration nightmares. API versioning, schema validation, backward compatibility — these are not optional when multiple teams depend on your service.
With agents, the contract discipline is even more critical because ambiguity is where unpredictable behavior lives.
Define what each agent accepts and produces — ideally with structured outputs you can validate:
{
"agent": "refund_eligibility",
"input_schema": {
"order_id": "string",
"reason_code": "enum[damaged, late, wrong_item, changed_mind]",
"days_since_delivery": "integer"
},
"output_schema": {
"eligible": "boolean",
"refund_amount": "number",
"refund_method": "enum[original_payment, store_credit]",
"explanation": "string"
}
}You must be equally explicit about tool contracts. Define what tools can be called, with what parameters, what data can be accessed, and what side effects are allowed. This is how you prevent prompt drift from turning into system drift — a phrase from the Red Hat article that stuck with me because it perfectly describes a failure mode I have seen in production agent systems.
A strong contract mindset also improves portability. When your tools and agent steps have stable interfaces, you can swap models, change retrieval methods, or add new workflow steps without rewriting the whole system. This is the same benefit that well-defined service interfaces gave us in the microservices world.
Reliability Patterns Carry Over
Microservices taught backend engineers to assume failure. Networks drop. Dependencies degrade. Tail latency ruins user experience. Agentic systems have the same issues plus a few new ones:
- Tool calls fail or return unexpected formats
- Retrieval returns irrelevant context that degrades reasoning quality
- Inference latency spikes during high-traffic periods
- Model outputs occasionally violate the expected schema
The same operational playbook applies:
flowchart TD
A["Agent Tool Call"] --> B{"Success?"}
B -->|Yes| C["Process Result"]
B -->|No| D{"Retry Count
< Max?"}
D -->|Yes| E["Backoff + Retry"]
E --> A
D -->|No| F{"Circuit Open?"}
F -->|No| G["Open Circuit Breaker"]
G --> H["Use Fallback
(cached result / graceful degradation)"]
F -->|Yes| H
Timeouts — do not let a single slow tool call block the entire workflow. Set explicit timeouts and decide what happens when they fire.
Retries with exponential backoff — transient failures in tool calls or inference are common. Retry, but do not hammer the dependency.
Circuit breakers — if a tool or model endpoint is consistently failing, stop calling it and fall back to a degraded but functional path.
Idempotency — design tool calls so that retries do not create duplicate side effects. If your agent calls a payment API and the first call times out, the retry should not charge the customer twice. This is the same idempotency discipline that backend engineers apply to message queues and event-driven systems.
Fallback behaviors — when the primary model is slow or unavailable, can you fall back to a smaller, faster model for a subset of the task? When retrieval fails, can you proceed with reduced context and flag the uncertainty?
This is where agentic design becomes an engineering discipline rather than a prompt engineering exercise. You are making explicit tradeoffs about latency, cost, and correctness — the same tradeoffs backend engineers make every day.
Observability: Tracing Decisions, Not Just Requests
In microservices, we trace requests through services. In agentic systems, we also need to trace decisions through workflow steps.
When an agent produces a wrong result, you need to answer: did the failure come from retrieval (wrong context pulled in), tool invocation (API returned bad data), or the model’s reasoning (hallucination despite correct inputs)? Without step-level observability, debugging an agentic workflow is like debugging a microservices system without distributed tracing — possible, but painfully slow.
What to capture:
- Per-step traces — input, output, latency, and token usage for each agent in the pipeline
- Tool call details — request payload, response payload, status code, duration
- Retrieval quality signals — what was retrieved, relevance scores, what was actually used in the final reasoning
- End-to-end correlation — a single trace ID that spans the entire workflow from client request to final response
flowchart LR
A["Client
Request"] --> B["Orchestrator
(trace_id generated)"]
B --> C["Retrieval Agent
(span: retrieval)"]
C --> D["Validation Agent
(span: validation)"]
D --> E["Execution Agent
(span: execution)"]
E --> F["Tool Call
(span: tool.payment_api)"]
E --> G["Model Inference
(span: inference)"]
F & G --> H["Response Agent
(span: response)"]
H --> I["Client
Response"]
B & C & D & E & F & G & H -.->|"spans collected"| J["Observability
Platform"]
Without observability, agentic AI stays stuck in the prototype stage. With it, teams can tune quality, reduce cost, and improve reliability with the same confidence they bring to production backend operations.
The Backend Mindset Shift
Here is what I find most interesting about this whole trend: building reliable AI agents is not a new skill set for backend engineers. It is an extension of the existing one.
The shift is not from “backend engineer” to “AI engineer.” It is from:
- “I build services that call other services” → “I build agents that coordinate models, tools, and data"
- "I design API contracts” → “I design agent contracts and tool schemas"
- "I implement circuit breakers for downstream dependencies” → “I implement resilience patterns for inference and tool calls"
- "I set up distributed tracing” → “I set up decision tracing across agent workflows”
flowchart TB
subgraph before["Traditional Backend"]
direction LR
A1["API Gateway"] --> B1["Service A"]
B1 --> C1["Service B"]
C1 --> D1["Database"]
B1 --> E1["External API"]
end
subgraph after["Agentic Backend"]
direction LR
A2["Orchestrator"] --> B2["Retrieval Agent"]
B2 --> C2["Reasoning Agent"]
C2 --> D2["Vector DB + Traditional DB"]
C2 --> E2["Tool Calls + Model Inference"]
end
before -->|"Same patterns,
new components"| after
The tools change, but the engineering discipline remains the same. If you know how to design bounded contexts in domain-driven design, you can design bounded responsibilities for agents. If you know how to set up SLOs for a REST API, you can set up SLOs for an agent workflow (latency, accuracy, cost per request). If you know how to do blue-green deployments for services, you can do A/B deployments for agent versions.
This is why the framing of agentic AI as a distributed system is so powerful. It takes something that feels new and intimidating and maps it onto decades of hard-won backend engineering knowledge.
What I Am Still Figuring Out
To be honest, there are parts of this analogy that do not map perfectly — and I think it is worth being upfront about that.
Nondeterminism — Microservices are generally deterministic. Given the same input, Service A produces the same output. LLM-based agents are not. The same prompt can produce different results on different runs. This means testing and verification strategies need to be fundamentally different — more like statistical quality assurance than unit testing.
Cost models — In microservices, the cost of a service call is relatively predictable (compute + network). In agent systems, cost varies dramatically based on token usage, model choice, and the number of reasoning steps. Cost observability becomes a first-class concern in a way it rarely was for traditional services.
Debugging reasoning — When a microservice returns a wrong result, you can usually trace it to a specific code path. When an agent makes a bad decision, the “code path” is the model’s internal reasoning — which is not directly inspectable. Techniques like chain-of-thought logging help, but it is not the same as stepping through a debugger.
Versioning semantics — What does it mean to “version” an agent? Is it the prompt version? The model version? The tool schema version? All of the above? Microservices versioning is already complex, but at least we have established conventions (semver, API versioning). Agent versioning is still an open question.
These are not reasons to avoid the microservices-to-agents mapping — it is still the most useful mental model I have found. But they are areas where the analogy breaks down and new patterns will need to emerge.
Practical Takeaways
If you are a backend engineer exploring agentic AI (or being asked to build agent systems at work), here is what I would suggest based on this microservices lens:
Start with decomposition — resist the temptation to build one smart agent. Break the workflow into smaller agents with clear responsibilities, just like you would decompose a monolith into services.
Define contracts early — structured input/output schemas for each agent and tool. This prevents the “it works in my demo” syndrome that plagues agent prototypes.
Build resilience from day one — timeouts, retries, circuit breakers, fallbacks. Do not wait until production to discover that your agent workflow fails catastrophically when a single tool call times out.
Invest in observability before scaling — step-level tracing, tool call logging, cost tracking. You cannot improve what you cannot measure.
Apply idempotency to tool calls — especially for agents that interact with external APIs or databases. Retries should be safe by default.
Treat prompt engineering as API design — the same care you put into designing a REST API (clear naming, validation, documentation, versioning) should go into designing agent prompts and tool definitions.
The broader point is this: backend engineers are not being replaced by AI agents. Backend engineers are the ones best equipped to build reliable agent systems — because the hard problems in agentic AI (decomposition, contracts, resilience, observability, governance) are the same hard problems we have been solving for years in distributed systems.
The components are new. The engineering discipline is not.
References: