
จาก Monolithic Agents สู่ Composable Workflows: สิ่งที่ Microservices สอนเราเรื่องการสร้าง AI Agents ที่เชื่อถือได้
ถ้าคุณเคยทำงาน backend มานานพอ น่าจะเคยผ่านช่วง migration จาก monolith ไป microservices มาแล้วสักครั้งครับ ความเจ็บปวดของการแกะ codebase ก้อนใหญ่ออกเป็น service ย่อยๆ ที่ deploy ได้อิสระ learning curve เรื่อง service contracts, circuit breakers, distributed tracing และ operational overhead ต่างๆ ที่มาพร้อมกัน
ตอนนี้ มองไปที่วิธีที่ AI agents ถูกสร้างขึ้นในปัจจุบัน pattern เดียวกันนี้กำลังเกิดขึ้นอีกครั้งครับ — แค่เปลี่ยนโดเมน
หลังจากอ่านบทความและ discussion หลายชิ้นเกี่ยวกับ agentic AI architecture (โดยเฉพาะ บทความของ Suleiman Sadiq เรื่อง Red Hat’s approach) สิ่งหนึ่งที่ชัดเจนมากคือ: agentic AI คือ distributed system และ engineering principles เดียวกันที่ทำให้ microservices ประสบความสำเร็จ — explicit contracts, decomposition, resilience, และ observability — นำมาใช้ได้โดยตรง
โพสต์นี้คือความพยายามของผมในการเชื่อมจุดเหล่านี้จากมุมมองของ backend engineer ครับ
ทำไม Analogy นี้ถึงสำคัญ
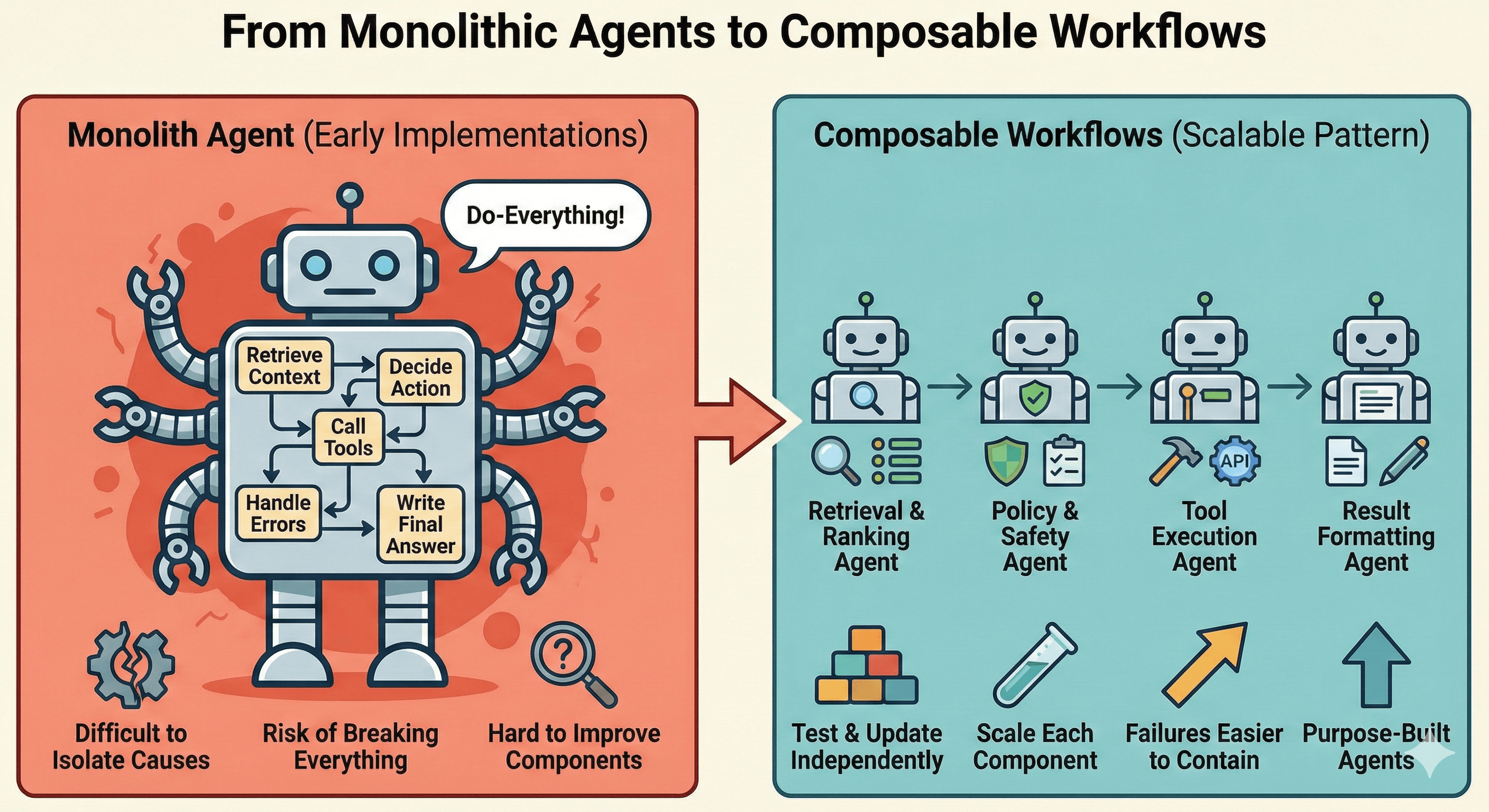
ตอนที่ผมเริ่มศึกษา AI agents ที่ซับซ้อนกว่า prompt-response chain ง่ายๆ implementation แรกๆ ให้ความรู้สึกคุ้นๆ ในแบบที่ไม่ค่อยสบายใจ Agent ตัวเดียวที่ดึง context, ตัดสินใจว่าจะทำอะไร, เรียก tools, จัดการ errors, แล้วก็สร้างคำตอบสุดท้าย สะดวกดี — แต่มันก็คือ AI equivalent ของ monolith นั่นเอง
ถ้าคุณเคย maintain monolithic backend service ที่ทำทุกอย่าง — authentication, business logic, data access, ส่ง notification, reporting — คุณน่าจะเข้าใจความเจ็บปวดนี้ดี เวลาอะไรพัง การแยก root cause ทำได้ยาก เวลาอยากปรับปรุงส่วนหนึ่ง ก็เสี่ยงพังส่วนอื่น การ deploy กลายเป็นเรื่อง high-risk
ปัญหาเดียวกันนี้เกิดขึ้นกับ monolithic agents และ solutions เดียวกันก็ใช้ได้ครับ
flowchart LR
subgraph monolith["Monolithic Agent"]
direction TB
A["Retrieve Context"]
B["Decide Action"]
C["Call Tools"]
D["Handle Errors"]
E["Format Response"]
A --> B --> C --> D --> E
end
subgraph composable["Composable Workflow"]
direction TB
F["Retrieval Agent"]
G["Validation Agent"]
H["Execution Agent"]
I["Response Agent"]
end
monolith -->|"Decompose"| composable
Microservices-to-Agents Mapping
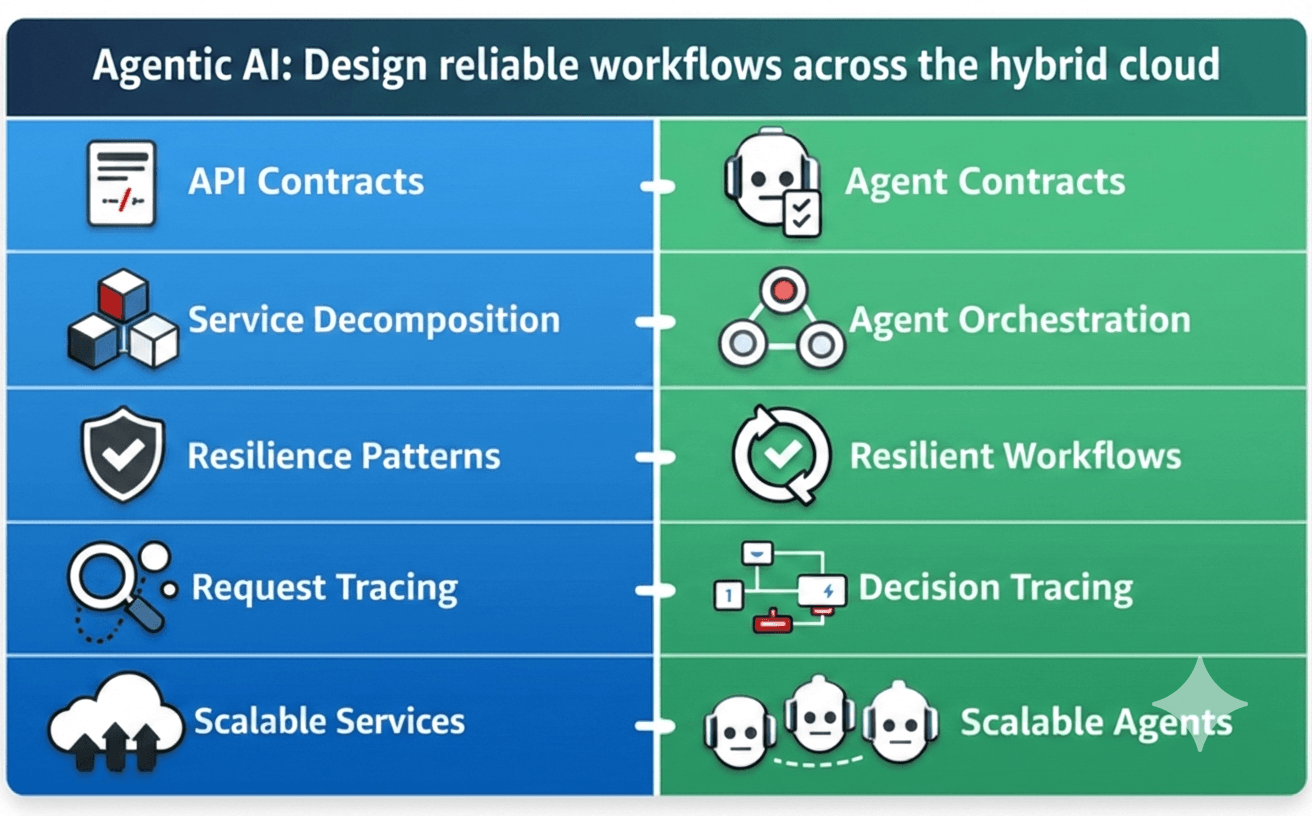
สิ่งที่ทำให้ analogy นี้ใช้ได้จริง (ไม่ใช่แค่ทฤษฎี) คือ patterns ต่างๆ map ตรงกันขนาดไหน นี่คือตารางเปรียบเทียบที่ผม resonate ด้วยครับ:
| Microservices Pattern | Agentic AI Equivalent |
|---|---|
| API contracts (OpenAPI, gRPC) | Structured input/output schemas (JSON Schema) สำหรับ agents |
| Service decomposition | แตก agent ก้อนใหญ่ออกเป็น purpose-built agent pipeline |
| Circuit breakers & retries | Timeouts, fallbacks, และ retry logic สำหรับ tool calls และ inference |
| Distributed tracing (Jaeger, Zipkin) | Step-level traces ข้าม agent workflow (tool calls, reasoning, retrieval) |
| Independent scaling | Scale inference, retrieval, และ tool execution แยกกัน |
| API gateway / service mesh | Orchestrator layer ที่ route ระหว่าง agents |
| Governance & compliance | Tool allowlists, data access policies, prompt guardrails |
นี่ไม่ใช่ analogy ที่ฝืนมาครับ ถ้ามองดีๆ agent ที่เรียก tool ผ่าน API มันมีโครงสร้างเหมือนกับ service ที่เรียก service อื่นผ่าน HTTP เป๊ะเลย failure modes เหมือนกัน: latency spikes, partial failures, versioning mismatches, security boundary violations เรื่อง operational ก็เหมือนกัน: จะ observe ยังไง, จะ scale ยังไง, จะ rollback ยังไงเวลาอะไรพัง
จาก Agent ก้อนเดียวสู่ Composable Workflows
หลักการ decomposition จาก microservices เป็น pattern ที่ impact มากที่สุดเมื่อนำมาใช้กับ agents
แทนที่จะมี agent ตัวเดียวที่ทำทุกอย่าง ให้แตก workflow ออกเป็น agents ย่อยๆ ที่ถูกสร้างมาเฉพาะงาน แล้ว orchestrate เป็น pipeline:
flowchart LR
A["Client Request"] --> B["Orchestrator"]
B --> C["Retrieval Agent
(fetch & rank context)"]
C --> D["Validation Agent
(check policy & safety)"]
D --> E["Execution Agent
(call tools & APIs)"]
E --> F["Response Agent
(format & deliver)"]
F --> G["Client Response"]
แต่ละ agent มี single responsibility ครับ test, update, และ scale แต่ละตัวได้อิสระ เวลา retrieval quality ลดลง ก็รู้เลยว่าต้องไปดูที่ไหน เวลาอยากเปลี่ยน model ที่ใช้ใน execution step ก็ไม่ต้องกลัวว่า validation logic จะพัง failures จะถูกกักไว้ในขอบเขต ไม่ cascade ลามทั้งระบบ
ตัวอย่างจริง: Order Processing Agent
เพื่อให้เห็นภาพชัดขึ้น ลองนึกถึง workflow การจัดการคำสั่งซื้อของ e-commerce ถ้าใช้ monolithic agent approach จะเป็นแบบนี้:
"You are an order processing agent. When a customer asks about their order,
look up the order in the database, check shipping status from the logistics API,
calculate any refund eligibility, and respond with all relevant details.
Handle errors gracefully."prompt เดียวทำหลายเรื่องเกินไป ถ้าใช้ composable approach:
flowchart TD
A["Customer Query"] --> B["Intent Agent
'What is the customer asking?'"]
B -->|Order Status| C["Order Lookup Agent
(DB query + caching)"]
B -->|Refund Request| D["Refund Eligibility Agent
(policy rules + calculation)"]
B -->|Shipping Question| E["Logistics Agent
(API call to carrier)"]
C & D & E --> F["Response Composer Agent
(format for channel)"]
F --> G["Customer Response"]
แต่ละ agent test แยกกันได้ครับ Intent Agent สามารถ evaluate กับ labeled dataset ได้ Refund Eligibility Agent สามารถ unit test กับ policy rules ได้ Logistics Agent สามารถ mock ได้ตอน development ข้อดีด้าน testability เหมือนกับที่ microservices ให้เราเมื่อเทียบกับ monolith เลย
Contracts: ยิ่งสำคัญกว่าเดิมกับ Agents
ใน microservices ทีมต่างๆ เรียนรู้อย่างเจ็บปวดว่า services ที่ไม่มี explicit contracts จะนำไปสู่ฝันร้ายของ integration API versioning, schema validation, backward compatibility — สิ่งเหล่านี้ไม่ใช่ optional เมื่อหลายทีมต้องพึ่งพา service ของคุณ
กับ agents นั้น contract discipline ยิ่งสำคัญกว่าเดิมเพราะ ความคลุมเครือคือจุดที่ unpredictable behavior อาศัยอยู่
กำหนดให้ชัดว่าแต่ละ agent รับอะไรเข้ามาและส่งอะไรออกไป — ควรเป็น structured outputs ที่ validate ได้:
{
"agent": "refund_eligibility",
"input_schema": {
"order_id": "string",
"reason_code": "enum[damaged, late, wrong_item, changed_mind]",
"days_since_delivery": "integer"
},
"output_schema": {
"eligible": "boolean",
"refund_amount": "number",
"refund_method": "enum[original_payment, store_credit]",
"explanation": "string"
}
}ต้อง explicit เรื่อง tool contracts เช่นกัน กำหนดว่า tools ไหนเรียกได้ ด้วย parameters อะไร เข้าถึง data อะไรได้ และ side effects อะไรที่อนุญาต นี่คือวิธีป้องกัน prompt drift ไม่ให้กลายเป็น system drift — วลีจากบทความ Red Hat ที่ติดหัวผมเพราะมัน describe failure mode ที่เคยเจอใน production agent systems ได้เป๊ะมาก
Contract mindset ที่แข็งแกร่งยังช่วยเรื่อง portability ด้วยครับ เมื่อ tools และ agent steps มี stable interfaces ก็สามารถเปลี่ยน model, เปลี่ยน retrieval method, หรือเพิ่ม workflow steps ใหม่ได้โดยไม่ต้อง rewrite ทั้งระบบ ข้อดีเดียวกับที่ well-defined service interfaces ให้เราในโลก microservices
Reliability Patterns ใช้ได้เหมือนเดิม
Microservices สอน backend engineers ให้ สันนิษฐานว่าจะพัง Network หลุด Dependencies ทำงานช้าลง Tail latency ทำลาย user experience ระบบ Agent มีปัญหาเหมือนกัน บวกปัญหาใหม่อีกหลายอย่าง:
- Tool calls ล้มเหลวหรือ return format ที่ไม่คาดคิด
- Retrieval ดึง context ที่ไม่เกี่ยวข้องมาจน reasoning quality ลดลง
- Inference latency พุ่งสูงช่วง traffic หนาแน่น
- Model outputs บางครั้งละเมิด expected schema
Operational playbook เดิมใช้ได้ครับ:
flowchart TD
A["Agent Tool Call"] --> B{"Success?"}
B -->|Yes| C["Process Result"]
B -->|No| D{"Retry Count
< Max?"}
D -->|Yes| E["Backoff + Retry"]
E --> A
D -->|No| F{"Circuit Open?"}
F -->|No| G["Open Circuit Breaker"]
G --> H["Use Fallback
(cached result / graceful degradation)"]
F -->|Yes| H
Timeouts — อย่าปล่อยให้ tool call ที่ช้าตัวเดียว block ทั้ง workflow ตั้ง timeout ให้ชัดเจนและตัดสินใจว่าจะทำอะไรเมื่อ timeout เกิดขึ้น
Retries with exponential backoff — transient failures ใน tool calls หรือ inference เป็นเรื่องปกติ retry ได้ แต่อย่าถล่ม dependency
Circuit breakers — ถ้า tool หรือ model endpoint fail ต่อเนื่อง ให้หยุดเรียกและ fall back ไปใช้ path ที่ทำงานได้แม้จะลด capability ลงบ้าง
Idempotency — ออกแบบ tool calls ให้ retry แล้วไม่เกิด side effects ซ้ำ ถ้า agent เรียก payment API แล้ว call แรก timeout การ retry ต้องไม่ charge ลูกค้าซ้ำ discipline เดียวกับที่ backend engineers ใช้กับ message queues และ event-driven systems
Fallback behaviors — เมื่อ primary model ช้าหรือ unavailable สามารถ fall back ไปใช้ model เล็กที่เร็วกว่าสำหรับ subset ของงานได้ไหม? เมื่อ retrieval fail สามารถทำงานต่อด้วย context ที่น้อยลงแล้ว flag ความไม่แน่นอนได้ไหม?
ตรงนี้แหละที่ agentic design กลายเป็น engineering discipline แทนที่จะเป็นแค่ prompt engineering exercise คุณกำลัง tradeoff อย่างชัดเจนระหว่าง latency, cost, และ correctness — tradeoffs เดียวกับที่ backend engineers ทำทุกวัน
Observability: Trace การตัดสินใจ ไม่ใช่แค่ Requests
ใน microservices เรา trace requests ที่ไหลผ่าน services ในระบบ agent เราต้อง trace การตัดสินใจที่ไหลผ่าน workflow steps ด้วย
เมื่อ agent ให้ผลลัพธ์ผิด คุณต้องตอบให้ได้ว่า: failure มาจาก retrieval (ดึง context ผิด), tool invocation (API return ข้อมูลไม่ดี), หรือ model reasoning (hallucination ทั้งที่ inputs ถูกต้อง)? ถ้าไม่มี step-level observability การ debug agentic workflow ก็เหมือนกับการ debug microservices system โดยไม่มี distributed tracing — ทำได้ แต่ช้าจนเจ็บปวด
สิ่งที่ควร capture:
- Per-step traces — input, output, latency, และ token usage ของแต่ละ agent ใน pipeline
- Tool call details — request payload, response payload, status code, duration
- Retrieval quality signals — อะไรถูกดึงมา, relevance scores, อะไรถูกนำไปใช้จริงใน reasoning สุดท้าย
- End-to-end correlation — trace ID เดียวที่ span ทั้ง workflow ตั้งแต่ client request ถึง final response
flowchart LR
A["Client
Request"] --> B["Orchestrator
(trace_id generated)"]
B --> C["Retrieval Agent
(span: retrieval)"]
C --> D["Validation Agent
(span: validation)"]
D --> E["Execution Agent
(span: execution)"]
E --> F["Tool Call
(span: tool.payment_api)"]
E --> G["Model Inference
(span: inference)"]
F & G --> H["Response Agent
(span: response)"]
H --> I["Client
Response"]
B & C & D & E & F & G & H -.->|"spans collected"| J["Observability
Platform"]
ถ้าไม่มี observability, agentic AI จะค้างอยู่ในขั้น prototype ไปตลอด แต่ถ้ามี ทีมสามารถ tune quality, ลด cost, และปรับปรุง reliability ด้วยความมั่นใจเดียวกับที่ใช้ใน production backend operations
Backend Mindset Shift
นี่คือสิ่งที่ผมว่าน่าสนใจที่สุดเกี่ยวกับ trend นี้ครับ: การสร้าง AI agents ที่เชื่อถือได้ ไม่ใช่ skill set ใหม่สำหรับ backend engineers มันคือ extension ของ skill set เดิม
การเปลี่ยนแปลงไม่ใช่จาก “backend engineer” เป็น “AI engineer” แต่คือจาก:
- “ผมสร้าง services ที่เรียก services อื่น” → “ผมสร้าง agents ที่ coordinate models, tools, และ data"
- "ผมออกแบบ API contracts” → “ผมออกแบบ agent contracts และ tool schemas"
- "ผม implement circuit breakers สำหรับ downstream dependencies” → “ผม implement resilience patterns สำหรับ inference และ tool calls"
- "ผม set up distributed tracing” → “ผม set up decision tracing ข้าม agent workflows”
flowchart TB
subgraph before["Traditional Backend"]
direction LR
A1["API Gateway"] --> B1["Service A"]
B1 --> C1["Service B"]
C1 --> D1["Database"]
B1 --> E1["External API"]
end
subgraph after["Agentic Backend"]
direction LR
A2["Orchestrator"] --> B2["Retrieval Agent"]
B2 --> C2["Reasoning Agent"]
C2 --> D2["Vector DB + Traditional DB"]
C2 --> E2["Tool Calls + Model Inference"]
end
before -->|"Same patterns,
new components"| after
tools เปลี่ยน แต่ engineering discipline ยังเหมือนเดิมครับ ถ้าคุณรู้วิธีออกแบบ bounded contexts ใน domain-driven design ก็ออกแบบ bounded responsibilities สำหรับ agents ได้ ถ้ารู้วิธีตั้ง SLOs สำหรับ REST API ก็ตั้ง SLOs สำหรับ agent workflow ได้ (latency, accuracy, cost per request) ถ้ารู้วิธีทำ blue-green deployments สำหรับ services ก็ทำ A/B deployments สำหรับ agent versions ได้
นี่คือเหตุผลที่การมอง agentic AI เป็น distributed system ถึงทรงพลังมาก มันเอาสิ่งที่ดูใหม่และน่ากลัว มา map กับความรู้ backend engineering ที่สั่งสมมาหลายสิบปี
สิ่งที่ผมยังคงกำลังเรียนรู้อยู่
พูดตามตรง มีบางส่วนของ analogy นี้ที่ map ไม่ได้สมบูรณ์แบบครับ — และผมคิดว่าควรพูดตรงๆ เรื่องนี้
Nondeterminism — Microservices โดยทั่วไปเป็น deterministic ใส่ input เดียวกัน Service A ให้ output เดียวกัน แต่ LLM-based agents ไม่ใช่ prompt เดียวกันอาจให้ผลต่างกันในแต่ละรอบ หมายความว่า testing และ verification strategies ต้องแตกต่างออกไปอย่างพื้นฐาน — เป็น statistical quality assurance มากกว่า unit testing
Cost models — ใน microservices, cost ของ service call ค่อนข้าง predictable (compute + network) แต่ในระบบ agent, cost ผันผวนมากขึ้นอยู่กับ token usage, model ที่เลือก, และจำนวน reasoning steps Cost observability กลายเป็นเรื่อง first-class concern ในแบบที่ไม่ค่อยเคยเป็นกับ traditional services
Debugging reasoning — เมื่อ microservice return ผลลัพธ์ผิด ปกติ trace ไปหา specific code path ได้ แต่เมื่อ agent ตัดสินใจผิด “code path” คือ internal reasoning ของ model — ซึ่ง inspect โดยตรงไม่ได้ เทคนิคอย่าง chain-of-thought logging ช่วยได้ แต่ไม่เหมือนกับการ step through debugger
Versioning semantics — “version” ของ agent หมายถึงอะไร? prompt version? model version? tool schema version? ทั้งหมดรวมกัน? Microservices versioning ซับซ้อนอยู่แล้ว แต่อย่างน้อยเรามี conventions ที่ established แล้ว (semver, API versioning) แต่ agent versioning ยังเป็นคำถามที่เปิดอยู่
สิ่งเหล่านี้ไม่ได้เป็นเหตุผลให้เลิกใช้ microservices-to-agents mapping — มันยังเป็น mental model ที่ useful ที่สุดที่ผมเจอ แต่มันคือจุดที่ analogy พังและ patterns ใหม่จะต้องเกิดขึ้นครับ
Practical Takeaways
ถ้าคุณเป็น backend engineer ที่กำลังศึกษา agentic AI (หรือถูกขอให้สร้าง agent systems ที่ทำงาน) นี่คือสิ่งที่ผมแนะนำจาก microservices lens ครับ:
เริ่มจาก decomposition — อย่ายอมแพ้ต่อความอยากสร้าง agent เก่งตัวเดียว แตก workflow ออกเป็น agents ย่อยที่มี responsibilities ชัดเจน เหมือนกับที่คุณจะ decompose monolith ออกเป็น services
กำหนด contracts ตั้งแต่เนิ่นๆ — structured input/output schemas สำหรับทุก agent และ tool ป้องกัน “works in my demo” syndrome ที่เกิดขึ้นบ่อยกับ agent prototypes
สร้าง resilience ตั้งแต่วันแรก — timeouts, retries, circuit breakers, fallbacks อย่ารอจนถึง production แล้วค่อยค้นพบว่า agent workflow พังยับเมื่อ tool call ตัวเดียว timeout
ลงทุนกับ observability ก่อน scale — step-level tracing, tool call logging, cost tracking วัดไม่ได้ก็ปรับปรุงไม่ได้
Apply idempotency กับ tool calls — โดยเฉพาะ agents ที่ interact กับ external APIs หรือ databases Retries ต้อง safe by default
ดูแล prompt engineering เหมือน API design — ความใส่ใจเดียวกับที่คุณใช้ออกแบบ REST API (clear naming, validation, documentation, versioning) ควรใช้กับการออกแบบ agent prompts และ tool definitions
ประเด็นใหญ่คือนี่ครับ: backend engineers ไม่ได้ถูกแทนที่โดย AI agents แต่ backend engineers คือคนที่พร้อมที่สุดในการสร้าง agent systems ที่เชื่อถือได้ — เพราะปัญหายากๆ ใน agentic AI (decomposition, contracts, resilience, observability, governance) คือปัญหาเดียวกับที่เราแก้มาหลายปีใน distributed systems
Components ใหม่ แต่ engineering discipline เดิมครับ
References: