

Fundamentals? คุณต้องรู้มากแค่ไหนสำหรับ Early Career ในปี 2026
บทสนทนาที่เจอเกือบทุกเดือน มักถามประมาณนี้: ยังต้องเรียน fundamentals อยู่ไหม? ต้องรู้มากแค่ไหนถึงจะเริ่มงานแรกได้?
โพสต์นี้พยายามตอบคำถามนั้น — ไม่ใช่เวอร์ชันที่ต้องอ่านหนังสือ 6-7 เล่มก่อนได้งานแรก และไม่ใช่เวอร์ชันที่ว่า fundamentals ไม่สำคัญแล้วเพราะมี Claude Code หรือ coding agent อยู่แล้ว ทั้งสองเวอร์ชันนั้นผิด
ในบทความนี้จะไปทีละหัวข้อ — data structures, networking, databases, operating systems, system design — แล้วแยกว่าอะไรต้องรู้เพื่อที่จะเริ่มต้นได้ อะไรต้องรู้เพื่อเติบโต สองอย่างนี้ต่างกัน และการเอามารวมกันคือสาเหตุที่ทำให้บางคนเตรียมตัวน้อยเกินไป หรืออีกทางก็พยายามทำให้ถึง bar ที่ไม่ใช่ entry-level bar จนหมดแรงกลางทาง
Why the Question Is Being Asked Wrong
ส่วนใหญ่จะถามว่า ต้องรู้ fundamentals เพื่อให้ได้งานไหม? และต้องรู้มากแค่ไหน? มีเรื่องที่ต้องรู้เต็มไปหมดเลย
คำถามที่ดีกว่าคือ ต้องรู้ fundamentals เพื่อให้เข้าใจว่าโค้ดหรือการแก้ปัญหาของตัวเองกำลังทำอะไรอยู่?
คำตอบคือ ใช่แน่นอน — เพราะความเข้าใจคือสิ่งที่แยก engineer ที่ debug ได้จาก engineer ที่ทำได้แค่เขียนใหม่, แยกคนที่ diagnose ปัญหาได้จากคนที่แค่เดา, แยกคนที่โตได้เรื่อยๆ จากคนที่ plateau หลังสองปี
สิ่งที่สังเกตเห็นใน engineer ที่ข้าม fundamentals ไป:
- ส่งโค้ดที่ทำงานได้กับ 100 rows แต่พังกับ 100,000 — เพราะไม่เข้าใจ complexity หรือ indexes
- อ่าน error ระดับ infrastructure ไม่ออก — 502 กับ 504 ต่างกันโดยสิ้นเชิง แต่รู้ได้ต่อเมื่อเข้าใจว่ามีอะไรอยู่ระหว่าง service กับ client
- เพิ่ม feature ได้แต่หาจุดที่ทำให้ system slowdown ไม่ได้ — ไม่มี mental model ว่า bottleneck อยู่ที่ไหน
- เจอ bug ที่ไม่คุ้นเคยแล้วไม่มีกรอบอ้างอิง เลือกเขียนใหม่แทนที่จะ fix
ทั้งหมดนี้ไม่เกี่ยวกับ interview trivia มันคือการทำงานให้ได้ตอนระบบพัง และใน production system ระบบพังแน่นอน
ในยุคที่ AI generate โค้ดได้เร็ว gap นี้เห็นได้ชัดขึ้น การ evaluate โค้ดที่ AI สร้างต้องอาศัยความเข้าใจว่าโค้ดที่ถูกต้องควรเป็นยังไง — รู้แค่ว่ามันดูน่าเชื่อถือนั้นยังไม่พอ Fundamentals คือสิ่งที่ทำให้แยกสองอย่างนั้นออกจากกัน
Floor ของ Entry Level
ก่อนจะไปทีละหัวข้อในเชิงลึก ขอตอบก่อน: ต้องรู้อะไรบ้างเพื่อเริ่มงานแรก?
นี่คือ minimum ที่นึกออก — ideal มันก็คือรู้ทั้งหมดน่ะแหละ แต่น้อยคน น้อยมาก ๆ ในโลกนี้ ที่จะเป็นแบบนั้น:
- Data structures: รู้จัก array และ hash map เข้าใจว่าทำไมถึงเลือกอันหนึ่งแทนอีกอัน มีความรู้สึกคร่าวๆ ว่า O(n) ช้ากว่า O(1) แค่นั้นพอ
- Networking: รู้ว่า HTTP คืออะไร เข้าใจ GET, POST, PUT, DELETE ในระดับ conceptual รู้ว่า 200, 400, 404, 500 แปลว่าอะไร รู้ว่า HTTPS หมายถึง connection ที่ถูก encrypt
- Databases: เขียน query พื้นฐานได้ — SELECT, INSERT, UPDATE, DELETE รู้ว่า index มีอยู่และทำให้ read เร็วขึ้น เข้าใจว่า transaction คืออะไรในระดับ conceptual (ทำงานทั้งหมดหรือไม่ทำงานเลย)
- Operating systems: รู้ว่า process กับ thread ต่างกัน แค่นั้นพอสำหรับวันแรก
- System design: รู้ว่า load balancer คืออะไร รู้ว่า cache มีอยู่และแก้ปัญหาอะไร
- Design diagrams: อ่าน class diagram อย่างง่ายได้และเข้าใจ relationship พื้นฐาน รู้ว่า sequence diagram แสดงอะไร รู้ว่า ER diagram แทนอะไร
อ้าว แต่ทุกอย่างในบทความนี้มันมีเกินกว่ารายการด้านบนนี่หว่า ไม่ใช่นะ ข้างล่างคือสิ่งที่เอาไว้เรียน ไม่ใช่ checklist ที่ต้องผ่านก่อนจะสมัครงานได้ นู่น ไอที่เพิ่งบอกไปเมื่อกี้นี้
ทำไมถึงรู้สึกว่า Bar สูงขึ้น
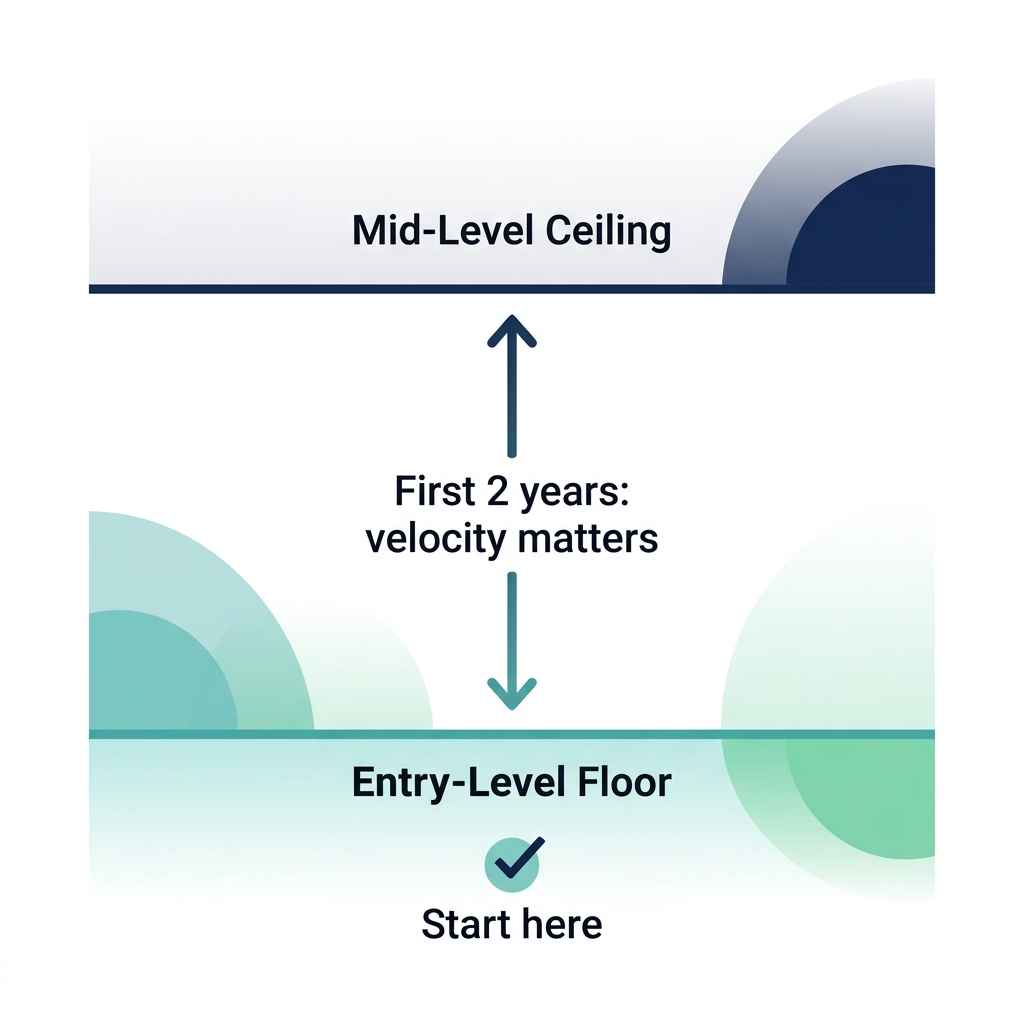
Floor สำหรับงานแรกไม่ได้เปลี่ยนไปมากนัก สิ่งที่เปลี่ยนคือ ceiling สิ่งที่คาดหวังจาก mid-level สูงขึ้น และบริษัทต้องการ early-career engineer ที่ ramp up ได้เร็ว แรงกดดันจาก ceiling นั้นส่งผลย้อนลงมา และทันใดนั้นความคาดหวังที่บรรยายว่าเป็น early career ก็ฟังดูเหมือนสิ่งที่เคยเป็น two-year mark
ดังนั้นเมื่อใครพูดว่า bar สูงขึ้นแล้ว พวกเขาพูดถูกเรื่อง mid-level expectations และผิดนิดหน่อยเรื่อง entry-level
Floor ยังเข้าถึงได้ สิ่งที่ต่างคือ velocity ที่คาดหวังหลังเริ่มงาน — เร็วแค่ไหนที่ต้องขยับจาก floor ไปหา ceiling ที่สูงขึ้น
อ่าน Ticket ให้ออก — แตก Problem ก่อนลงมือ
ก่อนจะไปทีละหัวข้อ technical มีทักษะการคิดอย่างหนึ่งที่ใช้ได้กับทุกส่วน: จะเข้าหางานแต่ละงานยังไงเมื่อมันมาถึงมือ
เมื่อเห็น ticket ใหม่ มีสามคำถามที่ต้องตอบก่อนเขียนโค้ดบรรทัดแรก
Feature นี้ใหญ่แค่ไหน? เป็นการแก้ไขไฟล์เดียว feature ที่แตะหลาย layer ของ stack หรืองานที่ต้องมี schema migration และ deployment window ที่กำหนดไว้? ประเด็นไม่ได้อยู่ที่การ estimate ให้แม่นยำ — estimate ผิดเกิดขึ้นได้ทุกระดับ ทักษะที่สำคัญคือดู ticket แล้วเห็นรูปร่างของงานก่อนรับ มันแตะ layer ไหนบ้าง ความซับซ้อนซ่อนอยู่ส่วนไหน Ticket ที่เขียนว่า รองรับ payment methods ดูเล็กจนกว่าจะ trace ดูว่ามันต้องทำอะไรบ้าง end to end
Subproblem มีอะไรบ้าง? Feature ไม่ได้ส่งเป็นก้อนเดียว ต้องแตกมันออกมา เช่น feature ให้ user top up wallet แตกได้เป็น: validate input, ตรวจสอบว่า wallet มีอยู่, สร้าง transaction แบบ PENDING, เรียก payment gateway, อัปเดต balance เมื่อสำเร็จ, จัดการแต่ละ failure case แต่ละ subproblem มันเล็ก test ได้ และเข้าใจแยกกันได้ ถ้าแตก feature ไม่ออก แสดงว่ายังไม่เข้าใจมันพอ — นั่นคือสัญญาณว่าควรหยุดก่อน ไม่ใช่สัญญาณให้เริ่มเขียน code
Frame แต่ละ subproblem เป็นภาษาพูดได้ไหม? เขียนประโยคสำหรับแต่ละอัน: เมื่อ wallet ไม่มีอยู่ ให้ return 404 และไม่สร้าง record ใด ประโยคนั้นคือ edge case, test case, และ documentation ในเวลาเดียวกัน Engineer ที่ข้ามขั้นตอนนี้มักจบลงด้วยการ debug behavior ที่ไม่เคยได้นึกถึงตั้งแต่แรก
flowchart TD T["Ticket or Requirement"] --> S["How large is this?"] S --> D["Break into subproblems"] D --> E["Frame each as a plain sentence"] E --> F["Map to technical components"]
สิ่งที่ได้จากกระบวนการนี้ไม่ใช่เอกสาร plan มันคือภาพในหัวที่ชัดเจนระดับนึง ควรอธิบายได้ว่ากำลังจะสร้างอะไร ทำในลำดับไหน เพราะอะไร — ก่อนเขียน function แรกด้วยซ้ำ แต่ถ้างานงอกทีหลัง อันนั้นก็เป็นอีกเรื่องนึง ที่บอกไปก่อนหน้า เราอาจจะ estimate ผิดหรือตกหล่นอะไรไป
อีกเรื่องหนึ่ง: ticket คือรูปแบบที่มีโครงสร้างมากที่สุดที่มีแล้ว (เท่าที่เขาจะใส่มาอ่ะนะ) เมื่อโตขึ้น input จะมีโครงสร้างน้อยลง ไม่ใช่มากขึ้น อาจเป็น product requirements document ที่ต้องดึง task ออกมาเอง อาจเป็น direction แบบกว้างๆ จาก tech lead ที่ต้องแปลงเป็น ticket เอง หรืออาจเป็นแค่ business goal ที่ไม่มี spec และต้องออกแบบทุกอย่างจากศูนย์
ถ้ารู้สึกว่างานเริ่ม parse ยากขึ้น — ยากตั้งแต่ขั้นนิยามมันออกมา ไม่ใช่ยากเชิง technical — นั่นไม่ได้แปลว่ามีอะไรผิดปกติ แต่เป็นสัญญาณว่าระดับ ownership กำลังเพิ่มขึ้น ความสามารถในการสร้างโครงสร้างจากความกำกวมคือสิ่งที่แยก engineer ที่ execute ออกจาก engineer ที่ lead และถ้ารู้สึกว่ายากขึ้น นั่นคือการเติบโต
Data Structures & Algorithms — ชั้นสำหรับ Evaluate
ขอเคลียร์ก่อน: เรื่องที่จะพูดไม่เกี่ยวกับการ grind LeetCode ประเด็นคือการเข้าใจ data structures ดีพอจะรู้ว่าเมื่อไหร่มีการเลือกใช้ที่เหมาะสมกับรูปแบบของข้อมูล
สิ่งที่ต้องรู้
Arrays และ dynamic arrays — structure ที่ทุกคน reach for เป็นอันดับแรก เข้าใจว่าทำไม random access ถึงเป็น O(1) แต่ insertion กลางกลุ่มถึงเป็น O(n) เรื่องนี้เจอบ่อยมากในโค้ดที่ insert ซ้ำๆ ไปที่หน้า list ข้างในลูป
Hash maps — น่าจะเป็น structure ที่ใช้บ่อยที่สุด เข้าใจว่า lookup เป็น O(1) โดยเฉลี่ย ไม่ใช่ทุกครั้ง เข้าใจ hash collision, load factor, และทำไม HashMap ถึงไม่ sorted รู้ว่าเมื่อไหร่ LinkedHashMap หรือ TreeMap สำคัญ ตัวอย่างที่เจอกันบ่อย: Redis (key-value store), DNS resolution (hostname → IP)
Linked lists — ไม่ค่อยใช้โดยตรง แต่จำเป็นสำหรับการเข้าใจ queues, LRU caches, และการทำงานของ memory allocation ข้างใน อีกทั้งการคิดแบบ pointer ยังช่วยเรื่อง tree traversal Pattern นี้โผล่ในระบบ: Git commit history (commit แต่ละก้อนชี้ไปยัง parent), blockchain (block แต่ละก้อนอ้างถึง block ก่อนหน้า), browser back/forward (doubly linked)
Trees — BST, heap, trie Heap สำคัญสำหรับ priority queues Trie สำคัญสำหรับ prefix search BST สำคัญสำหรับ sorted data operations ไม่ต้อง implement เองได้ในใจ แต่ต้องรู้ว่าเมื่อไหร่ควร reach for แต่ละอัน
Graphs — BFS และ DFS ไม่ใช่ interview tricks มันโผล่ใน dependency resolution, service mesh traversal, recommendation systems, และระบบที่มี relationship ใดๆ เข้าใจ adjacency list กับ matrix สำคัญเมื่อ graph มี sparse connections (ส่วนใหญ่ใน real-world เป็นแบบนี้) ตัวอย่างที่เห็นได้: social network friend graph, dependency tree ของ npm หรือ Maven
Stacks และ queues — รู้ความต่าง และรู้ว่าใช้ยังไงใน call stacks, undo systems, task queues, และ parsing
Complexity — ส่วนที่ใช้งานได้
Time และ space complexity ไม่ได้อยู่ที่การท่องสูตร มันอยู่ที่การมองโค้ดแล้วบอกได้ว่าโค้ดส่วนไหนจะพังตอน scale ใหญ่
flowchart LR
subgraph Acceptable["Acceptable for Most Cases"]
O1["O(1)
Constant
Hash lookup"] --> OlogN["O(log n)
Logarithmic
Binary search"] --> ON["O(n)
Linear
Single loop"] --> ONlogN["O(n log n)
Common Sort
Merge sort"]
end
subgraph Danger["Danger Zone at Scale"]
ON2["O(n²)
Quadratic
Nested loops"] --> ON3["O(n³)
Cubic
Triple nested"] --> O2N["O(2n)
Exponential
Brute-force"]
end
ONlogN -->|"gets expensive"| ON2
Nested loops ที่ควรเป็น hash maps คือแหล่งที่มาของ O(n²) ที่พบบ่อยใน production code — พลาดได้ง่ายถ้าอ่าน complexity ไม่ออก
สิ่งที่ข้ามได้
ไม่จำเป็นต้องรู้ red-black tree rotations ไม่ต้อง implement Dijkstra ในใจได้ ไม่ต้อง solve dynamic programming puzzles ภายใต้ความกดดัน สิ่งเหล่านี้เป็น interview gatekeeping tools ไม่ใช่ทักษะในชีวิตประจำวัน เรียนรู้ concept เบื้องหลัง dynamic programming (memoization, overlapping subproblems) — แต่ไม่ต้องเป็น DP wizard ในระดับ early career
Networking — รากฐานที่มองไม่เห็น
Networking คือจุดที่เห็นช่องว่างใหญ่ที่สุดใน engineer ระดับ early และ mid-level ทุกคนรู้ว่า HTTP คือ protocol ที่ web ใช้ แต่แทบไม่มีใครเข้าใจดีพอที่จะ debug มันได้
HTTP จากพื้นฐาน
ต้องเข้าใจ HTTP ลึกในระดับนึง พออ่านและใช้เซนส์ตัวเองได้ตอนระบบมันบึ้ม
Methods สำคัญ
- GET เป็น idempotent และไม่ควรเปลี่ยน state
- POST ไม่ใช่ idempotent
- PUT แทนที่ทั้งหมด
- PATCH แก้ไขบางส่วน
- DELETE ลบ
สิ่งเหล่านี้ไม่ใช่ convention — มี semantic meaning ที่สำคัญสำหรับ caching, retries, และ API design
การสลับ PUT กับ PATCH หรือใช้ GET กับ request ที่มี body ทำให้เกิดปัญหาที่โผล่ทีหลังในที่ที่คาดไม่ถึง
Status codes คือ vocabulary 200 คือ success 201 คือ created 204 คือ success ไม่มี body 400 คือความผิดของ client 401 คือ unauthenticated 403 คือ unauthorized 404 คือ not found 409 คือ conflict 422 คือ validation failure 500 คือ server error 502 คือ bad gateway (upstream ล้มเหลว) 503 คือ service unavailable 504 คือ gateway timeout (upstream ไม่ตอบทันเวลา)
รู้ความต่างระหว่าง 502 กับ 504 รู้ความต่างระหว่าง 401 กับ 403 มันบอกว่าควรไป debug ที่ไหน

Headers คือชั้น metadata Content-Type, Authorization, Cache-Control, Accept, X-Request-ID, CORS headers — จะได้เจอทั้งหมดนี้ เข้าใจว่า Authorization: Bearer <token> เป็น convention ไม่ใช่เวทมนตร์ เข้าใจว่า Cache-Control: no-store ป้องกัน caching ทุกชั้น เข้าใจว่า CORS error เป็น browser enforcement ไม่ใช่ network error
TCP — ทำไมสำคัญแม้ไม่เคยแตะ sockets
Engineer ส่วนใหญ่ใช้ TCP โดยไม่ต้องคิดอะไรมาก เพราะมันจัดการเรื่อง delivery ให้หมดแล้ว แต่ TCP ส่งผลกับงานประจำวันมากกว่าที่คิด:
- Connection establishment แพง ทุกครั้งที่เปิด connection ใหม่ต้องเสียเวลาทำ three-way handshake นี่คือเหตุผลที่ database client และ HTTP client ต้องมี connection pool ไว้ใช้ การไม่ใช้ pool เป็น shortcut ที่ทำให้เจอปัญหา latency เวลา scale ขึ้น
- TCP เป็น stateful หนึ่ง connection ผูกอยู่ระหว่างสอง endpoints เท่านั้น นี่คือเหตุผลที่ stateful service scale แบบ horizontal ได้ยาก
- Timeouts เป็นเรื่องของ TCP Connect timeout, read timeout, write timeout สามอันนี้คนละเรื่องกัน การตั้ง timeout เดียวครอบทั้งสามแบบเป็นข้อผิดพลาดที่เจอบ่อยมาก
sequenceDiagram participant C as Client participant LB as Load Balancer participant S as Server participant DB as Database C->>LB: Request LB->>S: Forward Note right of S: connect timeout means S is unreachable S->>DB: Query Note right of S: read timeout means S is too slow DB-->>S: Result Note right of LB: 504 timed out, 502 bad response from S S-->>LB: Response LB-->>C: Response
DNS — debug resolution chain
DNS failures เป็นเรื่องที่พบบ่อยและสร้างความสับสนถ้าไม่เข้าใจ resolution chain รู้ว่า:
- DNS ถูก cache หลายชั้น: browser, OS, resolver
- TTL (time-to-live) ควบคุมว่า cached entries ใช้ได้นานแค่ไหน
- เมื่อเปลี่ยน DNS records propagation ใช้เวลาเพราะ TTL
- ใน containerized environments DNS resolution ทำงานต่างออกไป — internal service names resolve ผ่าน path ต่างจาก public internet names
เมื่อ service บอก cannot resolve hostname นั่นคือปัญหา DNS เมื่อบอก connection refused service ล่มหรือไม่ได้ listen เมื่อบอก connection timeout host เข้าถึงได้แต่ไม่ตอบ Failure modes เหล่านี้ต่างกันและต้องการ fix ต่างกัน
TLS / HTTPS
TLS ไม่ใช่ optional ในปี 2026 ต้องเข้าใจ:
- Certificate chains: leaf, intermediate, root CA
- ทำไม certificate expiry ถึงทำให้เกิด incident (และ monitor ยังไง)
- ความต่างระหว่าง TLS termination ที่ load balancer กับ end-to-end TLS
- mTLS (mutual TLS) — จะเจอสิ่งนี้ใน service meshes และ microservice architectures
ไม่ต้อง implement TLS แต่ต้องเข้าใจดีพอที่จะ debug certificate errors และตัดสินใจว่าจะ terminate TLS ที่ไหนใน architecture
Databases — ที่ที่ App ส่วนใหญ่พัง
production incident ส่วนใหญ่ที่เจอมามีต้นเหตุมาจาก database ไม่ทางใดก็ทางหนึ่ง — missing index, query แย่ๆ, transaction deadlock, หรือเข้าใจ consistency model ผิด สำหรับงาน backend ประจำวัน database คือจุดที่ fundamentals สำคัญที่สุด
Indexes
Index แลก write performance กับ read performance เป็น trade-off พื้นฐานที่มักถูกมองข้าม โดยเฉพาะตอนที่ review schema change หรือ migration file
B-tree indexes
เป็น default ใน relational database ส่วนใหญ่ รองรับ range query, equality, prefix matching และเก็บข้อมูลแบบเรียงลำดับ ทำงานได้ดีกับ column ที่มี cardinality สูง
Composite indexes
เป็น index ที่ครอบหลาย column ลำดับของ column สำคัญมาก Index บน (user_id, created_at) ตอบ query ที่ filter เฉพาะ user_id ได้ หรือ filter ทั้งคู่ก็ได้ แต่ใช้กับ query ที่ filter เฉพาะ created_at ไม่ได้
Covering indexes
เก็บ column ทั้งหมดที่ query ต้องใช้ไว้ใน index เลย ทำให้ database ไม่ต้องไปอ่านจาก table เป็น optimization ที่ช่วยได้มากกับ query ที่อ่านบ่อย
Index selectivity
คืออัตราส่วนของค่าที่ไม่ซ้ำกันเทียบกับ row ทั้งหมด Index บน boolean column (มีแค่สองค่า) แทบไม่ช่วยอะไร Index บน UUID column (ค่าใกล้เคียง unique) มีประสิทธิภาพสูง
flowchart TD
Q["SELECT * FROM orders
WHERE user_id = 123
AND status = 'pending'"] --> P{Query Planner}
P -->|No index| A["Sequential Scan
Read every row
O(n) — slow at scale"]
P -->|Index on user_id| B["Index Scan on user_id
Filter status in memory
O(log n + k) — fast"]
P -->|Composite index
on user_id, status| C["Index Scan
Both conditions in index
Most efficient"]
A --> SLOW["⚠ 500ms+ on 1M rows"]
B --> OK["~5ms"]
C --> FAST["~1ms"]
เมื่อ review schema change หรือ migration file คำถามแรกที่ควรถามคือ: column ไหนอยู่ใน WHERE clause, JOIN condition, และ ORDER BY บ้าง? และมี index ครอบอยู่หรือยัง?
Transactions และ ACID
Atomicity
operation ทั้งหมดใน transaction สำเร็จพร้อมกัน หรือไม่สำเร็จทั้งหมด นี่คือสิ่งที่ป้องกัน partial update — เช่น ถ้าอัปเดต balance ของ user พร้อมกับสร้าง transaction record ก็ไม่อยากให้อันใดอันหนึ่งสำเร็จโดยที่อีกอันไม่สำเร็จ
Consistency
database จะเปลี่ยนจาก state ที่ valid ไปสู่ state ที่ valid อันใหม่เท่านั้น โดยมี constraint (foreign key, unique constraint, check constraint) คอยบังคับใช้
Isolation
concurrent transaction ไม่ควรรบกวนกัน เรื่องนี้ซับซ้อนที่สุดในสี่อัน
Durability
transaction ที่ commit แล้วต้องรอดแม้ระบบจะ crash อันนี้เป็นเรื่องของ write-ahead logging และการ flush ลง disk
Isolation level คือเรื่องที่ engineer ส่วนใหญ่มักมีช่องว่างความเข้าใจ:
- Read Uncommitted: อ่านข้อมูลจาก transaction ที่ยังไม่ commit ได้ ส่วนใหญ่ไม่ใช่สิ่งที่ต้องการ
- Read Committed: อ่านได้เฉพาะข้อมูลที่ commit แล้ว แต่ภายใน transaction เดียวกัน ถ้าอ่านซ้ำสองครั้งอาจได้ค่าต่างกัน (non-repeatable read)
- Repeatable Read: query เดิมจะ return ผลลัพธ์เดิมเสมอภายใน transaction เดียวกัน เป็น default ของ MySQL/InnoDB
- Serializable: transaction จะทำงานเสมือนรันทีละอัน ปลอดภัยที่สุด แต่ก็ช้าที่สุด
Application ส่วนใหญ่รันบน Read Committed ได้สบาย แต่ถ้ากำลังทำ financial logic, inventory reservation, หรือ check-then-act pattern ใดๆ ต้องคิดเรื่อง isolation level ให้รอบคอบ ซึ่งเป็นจุดที่ถูกข้ามไปได้ง่ายๆ
The N+1 Problem — Performance Bug ที่พบบ่อยที่สุด
นี่คือ performance issue ที่เจอบ่อยที่สุด มันเกิดจากการไม่เข้าใจว่า query ประกอบกันยังไง
// N+1 pattern — works fine locally, breaks in production:
const users = await User.findAll();
for (const user of users) {
const orders = await Order.findAll({ where: { userId: user.id } });
// 1 query for users + N queries for orders = N+1 queries
}
// What it should be:
const users = await User.findAll({ include: [{ model: Order }] });
// 1 query with JOIN = 1 query totalถ้ายังไม่รู้จัก N+1 ก็จะหามันไม่เจอตอน review code โค้ดแบบนี้รันใน development กับ user 10 คนก็ดูดี พอขึ้น production มี user 10,000 คน performance ก็พังทันที
N+1 — สิ่งที่เกิดขึ้นกับ database:
sequenceDiagram
participant App
participant DB
App->>DB: SELECT * FROM users
DB-->>App: user1, user2, ... userN
loop For each of N users
App->>DB: SELECT * FROM orders WHERE user_id = ?
DB-->>App: orders
end
Note over App,DB: 1 + N round trips to the database
วิธีแก้ — หนึ่ง query ด้วย JOIN:
sequenceDiagram participant App participant DB App->>DB: SELECT u.*, o.* FROM users u LEFT JOIN orders o ON u.id = o.user_id DB-->>App: all users with their orders in one response Note over App,DB: 1 round trip to the database
Query Planning — อ่าน EXPLAIN
EXPLAIN (หรือ EXPLAIN ANALYZE ใน PostgreSQL) จะแสดงให้เห็นว่า database วางแผน execute query ยังไง ต้องอ่านมันให้ออก สัญญาณสำคัญที่ต้องดู:
- Seq Scan: sequential scan อ่านทุก row ในตาราง ถ้าตารางเล็กก็พอเหมาะ แต่กับตารางใหญ่ที่ไม่มี WHERE clause ไปใช้ index แทบจะเป็นทางเลือกที่ผิดเสมอ
- Index Scan: ใช้ index ในการค้นหา ส่วนใหญ่ถือว่าดี
- Index Only Scan: อ่านจาก index ได้เลยโดยไม่ต้องไปแตะ table เป็น best case ของ covered query
- Hash Join / Nested Loop: วิธีที่ database ใช้ join ตาราง Nested loop จะแพงเมื่อ result set ใหญ่
- rows: ตัวเลขประมาณว่าจะ return กี่ row ถ้าค่าประมาณคลาดเคลื่อนจากที่ออกมามากๆ (เช่น ประมาณ 1 แต่ออกมา 100,000) แสดงว่า statistics ของตารางเก่าแล้ว
เป็นทักษะที่ค่อยๆ สร้างจากประสบการณ์ แต่อย่างน้อยพอเป็น mid-level ก็ควรรู้ว่ามันมีอยู่และอ่านพื้นฐานได้
Pagination — ทำไม OFFSET พังที่ scale
Pagination เป็นเรื่องที่เจอใน backend แทบทุกระบบ แต่วิธีทำแบบเริ่มต้นมักพังเมื่อโหลดหนัก
-- Common approach — looks fine, breaks at depth
SELECT * FROM transactions
WHERE wallet_id = 123
ORDER BY created_at DESC
LIMIT 20 OFFSET 1000OFFSET 1000 สั่ง database ให้อ่าน 1020 row แล้วทิ้ง 1000 row แรกไป ยิ่ง page ลึก ยิ่งทิ้งของมากขึ้น พอถึง page 500 (offset 10,000) database ต้อง scan 10,020 row จาก index แค่เพื่อ return 20 row
Keyset pagination แก้ปัญหานี้:
-- Client sends back the created_at of the last item they received
SELECT * FROM transactions
WHERE wallet_id = 123
AND created_at < '2026-01-15 10:30:00'
ORDER BY created_at DESC
LIMIT 20Database ใช้ index บน (wallet_id, created_at) แล้ว jump ไปที่ cursor ได้เลย ไม่มีการ scan แล้วทิ้ง row ไปฟรีๆ Performance คงที่ไม่ว่าจะอยู่ลึกแค่ไหนของ result set
flowchart LR
subgraph Offset["OFFSET Pagination"]
O1["Scan from start"] --> O2["Skip first 1000 rows"] --> O3["Return 20 rows"]
end
subgraph Keyset["Keyset Pagination"]
K1["Jump to cursor
via index"] --> K2["Return 20 rows"]
end
Offset -->|"gets slower
with each page"| SLOW["O(offset + limit)"]
Keyset -->|"constant speed"| FAST["O(log n + limit)"]
ข้อแลก: keyset pagination ไม่สามารถ jump ไปที่ page number ใดๆ ก็ได้ ทำได้แค่ next กับ previous แต่กับ use case ส่วนใหญ่ — transaction history, notification feed, infinite scroll — ก็ไม่ใช่ปัญหา
Time-bound queries — จับคู่ index กับรูปแบบ query
Date range query เป็น pattern ที่เจอบ่อยที่สุดใน backend โดยเฉพาะระบบที่มีงาน transaction รูปร่างของ index ต้องสอดคล้องกับรูปร่างของ query
-- Transactions for a wallet in the last 30 days
SELECT * FROM transactions
WHERE wallet_id = 123
AND created_at >= NOW() - INTERVAL '30 days'
ORDER BY created_at DESCQuery นี้ต้องใช้ composite index บน (wallet_id, created_at) พอมี index นี้ database จะ narrow ด้วย wallet ก่อน แล้วค่อย narrow ด้วย date range — ทั้งสอง condition ตอบได้ใน index scan เดียว ถ้าไม่มี created_at ใน index database จะดึง row ทั้งหมดของ wallet นั้นมาก่อน แล้วค่อย filter วันที่ใน memory ถ้า wallet มี 200 transaction ก็ยังไหว แต่ถ้ามี 200,000 ก็ช้าทันที
ในทางปฏิบัติ query สำหรับ transaction history มักรวมทั้งสอง pattern — ทั้ง time-bound และ paginated — เข้าด้วยกัน cursor ใน keyset pagination ก็คือ created_at ของ item ล่าสุดที่เห็น ส่วน date range ก็ทำหน้าที่จำกัดขอบเขตของ scan ไปในตัว
Operating Systems & Concurrency — ชั้นใต้โค้ด
Engineer ส่วนใหญ่มอง OS เป็น black box ถึงจุดหนึ่งก็ไม่เป็นไร แต่มี concepts บางอย่างที่รั่วออกมาเรื่อยๆ และถ้ามองข้ามไปจะเจอ bugs ที่ debug ยากมาก
Processes กับ threads กับ async — ไม่สามารถใช้แทนกันได้
Process
execution environment ที่ isolated มี memory space ของตัวเอง Processes ไม่ share memory โดย default การสื่อสารผ่าน IPC (pipes, sockets, shared memory) การ spawn process แพง
Thread
unit of execution ภายใน process Threads share memory นั่นคือสิ่งที่ทำให้เร็วและอันตรายพร้อมกัน — shared memory หมายถึง race conditions
Async/coroutines
cooperative multitasking ภายใน single thread ไม่มี parallelism แต่ concurrency สูงสำหรับ I/O-bound work Node.js ทำงานแบบนี้ และ async/await ใน Python ก็เช่นกัน Go’s goroutines เป็น model ต่างออกไป — lightweight threads ที่จัดการโดย Go runtime ซึ่งสามารถวิ่งพร้อมกันบน multiple CPU cores ทำให้ efficient ทั้งสำหรับ I/O-bound และ CPU-bound work อยู่ใกล้กับ mixed workloads มากกว่า pure async model
flowchart LR
subgraph CPU["CPU-Bound Work
(computation)"]
P["Multiple Processes
or Threads
True parallelism"]
end
subgraph IO["I/O-Bound Work
(waiting on network/disk)"]
A["Async / Event Loop
One thread, many tasks
No parallelism needed"]
end
subgraph Both["Mixed Workloads
(most web servers)"]
T["Thread Pool for CPU
+ Async for I/O"]
end
CPU --> Both
IO --> Both
ถ้า language/runtime ไม่ชัดในหัว จะเขียนโค้ดที่ไม่ scale หรือมี data corruption bugs ที่ Thread-unsafe access ไปยัง shared state สามารถพลาดได้ง่าย โดยเฉพาะในโค้ดที่ไม่ได้เขียนขึ้นมาโดยคิดถึง concurrency
Race conditions และ pattern พื้นฐานสำหรับป้องกัน
Race condition คือเมื่อผลลัพธ์ขึ้นอยู่กับ timing ของ concurrent operations ตัวอย่างคลาสสิก:
// Thread A and Thread B both read balance = 100
// Thread A adds 50: balance = 150, writes 150
// Thread B subtracts 30: balance = 70, writes 70
// Final balance: 70 — Thread A's write was lostSolutions ขึ้นอยู่กับ context:
- Mutex/lock: มีแค่ thread เดียวที่เข้าถึง critical section ในแต่ละครั้ง
- Atomic operations: hardware-level guarantees สำหรับ operations ง่ายๆ
- Immutability: ไม่ share mutable state — share copies หรือใช้ message passing
- Optimistic locking: check-and-set กับ version numbers (พบบ่อยใน databases)
ไม่ต้องเป็น concurrency expert ในระดับ early career แต่ต้องรู้จัก danger signs
และรู้ว่าเมื่อไหร่ที่ควรจะตั้งคำถาม: นี่คือ shared state ไหม? สอง threads เข้าถึงพร้อมกันได้ไหม?
Memory — stack กับ heap และทำไมสำคัญ
Stack: ขนาดคงที่ เร็ว จัดการอัตโนมัติ Local variables อยู่ที่นี่ Stack overflow เกิดขึ้นเมื่อ recurse ลึกเกินไป (stack เต็ม)
Heap: dynamic ใหญ่กว่า จัดการ manually (หรือ GC-managed) Objects, arrays, data ที่ allocate แบบ dynamic อยู่ที่นี่ Memory leaks เกิดที่นี่ — เมื่อถือ references ไปยัง objects ที่ไม่ต้องการแล้ว
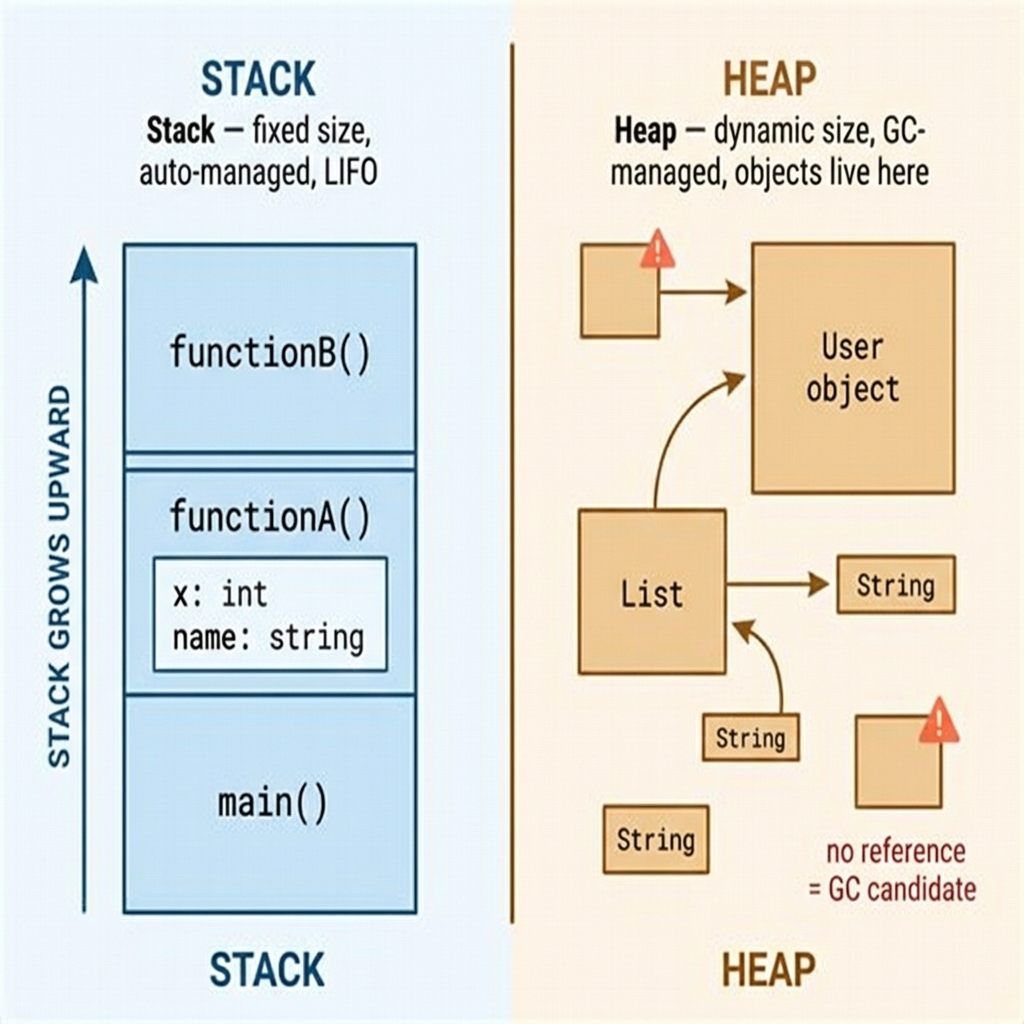
ใน garbage-collected languages (Java, Python, Go, JavaScript) ไม่ต้อง free memory ด้วยตัวเอง แต่ยังทำให้ memory leak ได้ด้วยการถือ references ที่ไม่ต้องการ
สาเหตุทั่วไปที่พบได้:
- Unbounded caches
- Event listeners ที่ไม่เคยถูก remove
- Closures ที่ capture objects ขนาดใหญ่
- Static collections ที่โตขึ้นไม่หยุด
การเข้าใจว่า GC มีอยู่และทำไมถึง pause application เป็นครั้งคราวสำคัญสำหรับ latency-sensitive services การเข้าใจ heap dumps และ memory profiling เป็นทักษะ mid-level ที่ควรมี
File descriptors และ connection limits
ทุก open file, socket, และ pipe คือ file descriptor Operating systems มีขีดจำกัดว่า process หนึ่งจะมี file descriptors เปิดได้กี่อัน ถ้ามี bug ที่เปิด connections แล้วไม่ปิด จะถึง limit นั้นและ service จะ fail ด้วย error ที่เราก็อาจจะงงว่า มันพังอะไรว้าาาาาา 😂
- นั่นคือเหตุผลที่ connection pooling สำคัญใน database clients
- นั่นคือเหตุผลที่ HTTP clients ควร reuse connections
- นั่นคือเหตุผลที่ต้อง close file handles หลังอ่านไฟล์เสมอ
System Design — ไม่ใช่แบบ Interview
System design แบบที่สอนใน interview prep (วาดกล่องบน whiteboard พูดว่า ต้องการ cache ต้องการ message queue เสร็จ) ไม่ใช่สิ่งที่พูดถึงที่นี่ — สิ่งที่หมายถึงคือการเข้าใจว่า components ทำอะไรได้ และ ทำอะไรไม่ได้
Load balancers — สิ่งที่มันทำ
Load balancer กระจาย incoming requests ไปยัง multiple instances ของ service
นอกจากนี้มันยังทำ:
- Health checking: ลบ instances ที่ fail health checks ออกจาก pool
- SSL termination: จัดการ TLS decryption เพื่อที่ service จะได้ไม่ต้องทำ
- Sticky sessions: route requests จาก client เดิมไปยัง instance เดิม (เกี่ยวข้องกับ stateful services)
สิ่งที่มันไม่ทำ: ไม่ทำให้ service กลายเป็น stateless ถ้า service เก็บ session state ใน memory การ load balance ข้าม instances จะทำให้เกิดปัญหา — request 1 อาจ build state บน instance A, request 2 ลงที่ instance B และ state หายไป
Message queues — async และ decoupling
Message queue (Kafka, RabbitMQ, SQS) decouples producer จาก consumer — Producer push ไปที่ queue แล้วก็ไปต่อ Consumer อ่านจาก queue ตาม pace ของตัวเอง
สิ่งที่แก้ได้:
- Backpressure: consumer ตามไม่ทัน producer — queue รับ burst ไว้
- Reliability: ถ้า consumer ล่ม messages รอใน queue แทนที่จะหายไปเฉย ๆ
- Decoupling: producer และ consumer ไม่ต้อง run พร้อมกัน
สิ่งที่แก้ไม่ได้:
- Ordering guarantees: queues ไม่ preserve order เสมอที่ scale — Kafka preserve ต่อ partition, SQS ไม่ guarantee ข้าม shards
- Exactly-once delivery: queues ส่วนใหญ่ให้ at-least-once ซึ่งหมายความว่า consumer ต้องจัดการ duplicate messages (idempotency)
- Transactions: การ write ไปที่ queue และ write ไปที่ database ใน atomic transaction เดียวกันทำยาก — ดู outbox pattern
flowchart LR API["API Service"] -->|"publish event"| Q["Message Queue at-least-once delivery"] Q -->|"consume"| W1["Worker 1"] Q -->|"consume"| W2["Worker 2"] W1 -->|"write"| DB["Database"] W2 -->|"write"| DB W1 -.->|"fail mid-process: message re-delivered"| Q
Caching — และทำไมการเพิ่ม cache ถึงไม่ใช่คำตอบที่สมบูรณ์ที่สุด
Caches แลก consistency กับ performance ทุก caching decision ต้องตอบให้ได้ว่า:
- Invalidation strategy คืออะไร? TTL (time-to-live), explicit invalidation, write-through, write-behind?
- เกิดอะไรขึ้นเมื่อ cache miss? ทุก miss ตี database หรือเปล่า? Thundering herd — เมื่อ cache หมดอายุและ 1,000 requests ตี database พร้อมกัน
- เกิดอะไรขึ้นเมื่อ cache ล่ม? Service degrade gracefully หรือ fail ทั้งหมด?
- Stale data ยอมรับได้ไหม? นานแค่ไหน?
การเพิ่ม cache ทำได้ง่าย แต่ทำให้สมบูรณ์แบบยากมาก ต้องตอบสี่คำถามด้านบนทั้งหมดก่อนที่การตัดสินใจจะครบถ้วน เขาบอกกันด้วยว่าเรื่อง Cache เป็น Hard Engineering Problem ด้วยซ้ำ
Failure modes — คำถามที่ต้องถาม
สำหรับทุก component ใน system ถาม:
- เกิดอะไรขึ้นถ้าอันนี้ช้า? (timeout, retry logic)
- เกิดอะไรขึ้นถ้าอันนี้ล่ม? (fallback, circuit breaker)
- เกิดอะไรขึ้นถ้าอันนี้ return ข้อมูลผิด? (validation, consistency checks)
- เกิดอะไรขึ้นถ้ามีสองอัน? (consistency, coordination)
flowchart TD
S["Service Call"] --> T{Response?}
T -->|Success| OK["Process normally"]
T -->|Timeout| RT["Retry with backoff
Dead letter if exhausted"]
T -->|Error 5xx| CB["Circuit breaker
Fail fast if repeated"]
T -->|Error 4xx| NR["Don't retry
Client error — fix the request"]
T -->|Down| FB["Fallback response
or graceful degradation"]
นี่ไม่ใช่ interview prep มันคือวิธีคิดกับ external dependency ทุกตัวที่ service เรียกใช้ — databases, third-party APIs, other microservices, message queues
Design Diagrams — คุยเรื่องโค้ดกับทีม
มีชั้นหนึ่งระหว่างการรู้วิธีเขียนโค้ดและการสื่อสาร design ไปยังทีม เป็นชั้นที่ควรพัฒนาตั้งแต่เนิ่นๆ — ไม่ใช่เพราะ UML เป็น requirement ที่เป็นทางการ แต่เพราะ visual language ที่ใช้ร่วมกันป้องกันความเข้าใจผิดใน design discussions, code reviews, และ architecture docs
วิธีที่ดีที่สุดในการเรียน diagram types คือผ่านปัญหาเดียวที่สอดคล้องกัน จะใช้ digital wallet / cashless payment system — domain ที่คุ้นเคย — แล้วมองจากสามมุม
Class diagrams — object relationships
Class diagrams แสดงว่า objects เชื่อมกันยังไงใน code: อะไร owns อะไร อะไรรู้เกี่ยวกับอะไร อะไร extends อะไร
5 relationships ที่ควรรู้:
- Composition (owns strongly): filled diamond ที่ owner Component ไม่สามารถมีอยู่ได้โดยปราศจาก parent — ลบ parent ออก component ก็ไปด้วย
- Aggregation (has loosely): hollow diamond ที่ owner Component มีอยู่ได้อิสระ — สามารถ belong ไปยัง parent ต่างออกไปหรือไม่มีเลย
- Association: plain arrow Objects รู้เกี่ยวกับกันและ interact กัน
- Dependency: dashed arrow Class หนึ่งใช้อีก class ชั่วคราว โดยไม่ถือ reference ถาวร
- Inheritance (is-a): hollow arrowhead ชี้ไปที่ parent Subclass เป็น specialization ของ parent
ใช้กับ digital wallet:
classDiagram User "1" *-- "1" Wallet : owns Wallet "1" *-- "many" Transaction : records User "1" o-- "many" PaymentMethod : has Transaction --> PaymentMethod : charged via Transaction --> Merchant : paid to WalletService ..> PaymentGateway : uses
อ่าน diagram นี้:
Walletowned โดยUserด้วย composition — ลบ user ออก wallet ก็ไปTransactionsถูก record โดยWalletด้วย composition — ไม่สามารถมีอยู่ได้โดยปราศจาก walletPaymentMethods(cards, bank accounts) ถูกถือด้วย aggregation — สามารถ detach หรือ reassign ได้Transactionเชื่อมกับทั้งPaymentMethodที่ใช้และMerchantที่จ่ายWalletServiceพึ่งพาPaymentGateway— เรียกมันทุก transaction แต่ไม่ได้ own มัน
Note: Wallet หนึ่งใบใช้ได้กับหลาย payment method ใน model นี้
PaymentMethodsถูกถือโดยUserไม่ใช่Walletดังนั้น wallet ใบเดียว (ต่อ user) ก็ charge ผ่าน card หรือ account ไหนก็ได้ที่ user link ไว้ ระบบ production อย่าง Stripe หรือ Apple Pay ก็ออกแบบแบบเดียวกัน — payment methods อยู่ที่ระดับ user/customer ส่วน wallet ทำหน้าที่ record รายการที่ใช้จ่าย
เหตุผลที่สำคัญใน practice: composition กับ aggregation กำหนดสิ่งที่เกิดขึ้นเมื่อ delete ทำผิดใน schema (missing CASCADE หรือ FK constraint ที่ผิด) แล้วจะ orphan records หรือลบข้อมูลที่ตั้งใจจะเก็บโดยไม่ตั้งใจ
Sequence diagrams — สิ่งที่เกิดขึ้นเมื่อ payment ถูก process
Sequence diagrams แสดง message flow ตามเวลา Domain digital wallet เดิม — สิ่งที่เกิดขึ้นเมื่อ user เริ่ม payment:
sequenceDiagram participant U as User participant App as Mobile App participant WS as Wallet Service participant DB as Database participant PG as Payment Gateway U->>App: Pay 500 THB to merchant App->>WS: POST /payments WS->>DB: Check wallet balance DB-->>WS: Balance OK WS->>DB: INSERT transaction (PENDING) WS->>PG: Charge payment method PG-->>WS: Approved WS->>DB: UPDATE transaction (COMPLETED) WS-->>App: 201 Created App-->>U: Payment confirmed
นี่แสดง two-phase pattern ที่พบบ่อยใน payment systems: สร้าง PENDING transaction ก่อน แล้วค่อยอัปเดตเป็น COMPLETED เมื่อ gateway ยืนยันเท่านั้น ถ้า gateway call ล้มเหลว transaction อยู่ที่ PENDING (หรือ rollback) — ไม่ mark ว่า COMPLETED ก่อนที่จะมีการยืนยัน
ในระดับ entry: อ่านได้และ trace ได้ว่าเกิดอะไรขึ้นถ้า gateway return error ในระดับ mid-level: สร้างสิ่งนี้ได้สำหรับ flow ที่กำลัง design
ER diagrams — database มีหน้าตาเป็นยังไง
ER diagrams แทน database schema: tables, columns, และ cardinality ของ relationships ระหว่างกัน
erDiagram
USER ||--|| WALLET : owns
USER ||--o{ PAYMENT_METHOD : has
WALLET ||--o{ TRANSACTION : records
MERCHANT ||--o{ TRANSACTION : receives
TRANSACTION }o--|| PAYMENT_METHOD : "charged via"
Domain เดิม คราวนี้มองในมุมของ schema สังเกตว่า class diagram และ ER diagram บอกเรื่องเดียวกันในระดับต่างกัน — อันหนึ่งเป็นเรื่องโครงสร้าง code อีกอันเป็นเรื่องโครงสร้าง database เมื่อสองอย่างไม่สอดคล้องกัน (code model ownership ต่างจากวิธีที่ schema enforce) bugs ตามมา
จุดของ shared language
เป้าหมายไม่ใช่ formal precision เป้าหมายคือทีมอ่าน design เดียวกันจาก diagram ที่วาด เมื่อแสดงปัญหาเดียวกันเป็น class diagram, sequence diagram, และ ER diagram ได้ กำลังสื่อสารในระดับที่ design discussions เกิดขึ้น — ไม่ใช่แค่ implement สิ่งที่คนอื่นตัดสินใจ
AI Era เปลี่ยนอะไรไปบ้าง
จะพูดให้ชัดขึ้น เพราะมี noise จากทั้งสองฝั่งมาก
AI ไม่ได้เปลี่ยน fundamentals Hash maps ยังเป็น hash maps TCP ยังมี three-way handshake Indexes ยังมี trade-offs สิ่งเหล่านี้ไม่ไปไหน
AI เปลี่ยนความเร็วที่ bad decisions กลายเป็น production code ก่อนจะมี AI tools การเขียนโค้ดใช้เวลา และเวลานั้นสร้าง friction ตามธรรมชาติในการคิด เคยเห็น senior engineer ที่เขียน query ด้วยมือแล้วหยุดคิดว่า เดี๋ยว column นี้ต้องการ index AI สร้าง 50 บรรทัดใน 3 วินาที มนุษย์ review ใน 5 วินาที Index หาย ส่งขึ้น production
AI สร้างโค้ดที่น่าเชื่อถือ ไม่ได้แปลว่าถูกต้องเสมอไป มี pattern ที่สอดคล้องกัน: AI สร้างโค้ดที่ทำงานได้สำหรับ happy path ใน test environment ที่ scale เล็ก Edge cases, failure modes, performance ที่ 1M rows — สิ่งเหล่านี้ต้องการความเข้าใจเพื่อจะจับได้
flowchart TD A["AI generates code"] --> B["Looks correct at a glance?"] B -->|Yes| C["Handles edge cases?"] B -->|No| FIX["Obvious fix — easy to catch"] C -->|Yes| D["Performs at scale?"] C -->|No| EDGE["N+1, missing validation Race condition — needs fundamentals to catch"] D -->|Yes| E["Handles failures?"] D -->|No| PERF["Missing index, O(n²) Needs CS knowledge to catch"] E -->|Yes| SHIP["Safe to ship"] E -->|No| FAIL["Missing timeout, no retry Needs system design to catch"]
Engineer ที่ทำงานได้ดีกับ AI tools ตอนนี้คือคนที่ใช้ AI เพื่อ generate และใช้ fundamentals เพื่อ evaluate Engineer ที่กำลังลำบากคือคนที่ generate แล้วส่งขึ้นโดยไม่ review
ใช้ AI เพื่อเรียน fundamentals
ด้านนี้มักถูกพูดถึงน้อยเกินไป การพูดส่วนใหญ่เกี่ยวกับ AI ใน engineering มุ่งที่ AI ในฐานะ code generator แต่จากที่ลองใช้ AI ยังเป็นเครื่องมือเรียนรู้ fundamentals ที่มีประโยชน์ — ถ้าเข้าหาในฐานะ active practice ไม่ใช่แค่การหาคำตอบ
วิธีที่ลองแล้วได้ผล:
Generate practice problems ตามต้องการ แทนที่จะทำ textbook exercises ลองถามว่า ให้ 5 real-world scenarios ที่การใช้ hash map เป็นทางเลือกที่ผิด และอธิบาย trade-off ในแต่ละอัน ถามต่อได้เรื่อยๆ ซึ่ง textbooks ทำไม่ได้
ทำงานกับ EXPLAIN outputs ด้วยความช่วยเหลือ เอา query จาก codebase ของตัวเอง run EXPLAIN ANALYZE แล้ว paste output ถาม AI ให้อธิบายว่าแต่ละ step หมายความว่าอะไร จากนั้น verify claims สำคัญกับ documentation ของ database การอธิบายจาก AI รวมกับการ verify ของเราเองสร้างความเข้าใจได้เร็วกว่า docs เพียงอย่างเดียว
Deliberate error spotting ขอให้ AI เขียนโค้ดที่มี flaw specific เช่น เขียน query ที่มีปัญหา N+1 หรือเขียน concurrent counter ที่มี race condition แล้วหาเองว่าอยู่ที่ไหน ควบคุม difficulty ได้เอง และถามหา hint หรือคำอธิบายทีหลังได้ — เป็น exercise ที่ชอบ
Probe ด้วย follow-up questions ลองถามว่า อธิบายว่าทำไม TCP connection establishment ถึงส่งผลต่อ database query latency แล้วต่อด้วย แปลว่าอะไรสำหรับค่า timeout default ใน JDBC connection pool? สามารถตาม confusion ที่มีแทนที่จะเดิน learning path ที่ textbook สมมติไว้
ความต่างสำคัญ: ใช้ AI เพื่อ skip ความเข้าใจ กับใช้ AI เพื่อเร่งความเข้าใจ ทั้งสองแบบทำให้เนื้อหาได้รับการอธิบาย มีแค่แบบเดียวที่ทำให้รู้มันได้เมื่อต้องใช้ตอนตี 2 ระหว่าง incident
สิ่งที่ไม่มีใครพูดถึง — Layoffs และใครรอดได้
ไม่มีใครเขียนเรื่องนี้ใน learn your fundamentals posts ดังนั้นจะเขียนเอง
ทุกบริษัทมี cash flow เมื่อการตัดสินใจเรื่อง headcount เกิดขึ้น คำถามที่กำลังตอบอยู่ — ไม่ว่าจะพูดออกมาหรือไม่ — คือ: output-to-cost ratio ของแต่ละคนเป็นเท่าไหร่? ถ้า engineer หนึ่งคนที่มี fundamentals แน่นและใช้ AI tools ได้ดีสามารถ produce ได้เท่ากับที่เคยต้องใช้สอง engineer คณิตศาสตร์ไม่ซับซ้อน — เห็นมากับตา Headcount decisions คือ cash flow decisions
ไม่ใช่เรื่องส่วนตัว ไม่ใช่เรื่องของ loyalty บริษัทไม่ใช่ครอบครัว ไม่ว่า all-hands presentations จะบรรยายพวกเขาแบบนั้นกี่ครั้งก็ตาม
Engineer ที่รอดจาก cut หลายรอบ หรือหาที่ใหม่ได้เร็วหลังโดน มักเป็นคนที่ evaluate code เป็น debug production issue ได้ และตัดสินใจเรื่อง architecture ได้ — ไม่ว่าจะเขียน draft แรกเองหรือ review งานที่ agent ทำมา คนกลุ่มนี้อยู่ที่ไหนก็มีคนต้องการ ไม่จำเป็นต้องฝืนอยู่กับบริษัทที่กำลัง layoff บริษัทที่เพิ่ง cut คนรอบหนึ่งก็ยัง hire คนใหม่อยู่ — แต่คัดเลือกมากขึ้น และ profile แบบนี้คือสิ่งที่เขาตามหา
Fundamentals ที่แน่นไม่ได้ทำให้ immune — product line ที่แย่หรือ quarter ที่แย่พา engineer ที่ดีลงด้วยเหมือนกัน แต่มันเปลี่ยนสิ่งที่เกิดขึ้นหลังจากนั้น — เร็วแค่ไหนที่ land ครั้งใหม่ได้
ถ้าต้องการ zero layoff risk มีทางเดียว: เปิดธุรกิจของตัวเอง ไม่มีใครไล่ออกได้ ไม่มี performance review มาแตะถึงในฐานะ founder
แต่มันมาพร้อมปัญหาคนละแบบ — Revenue ที่มาช้าหรือไม่มาเลย Customer ที่ ghost หลัง follow-up หลายรอบ Server ล่มตอนตีสาม และ on-call คือ… คุณคนเดียว ไม่มี colleague ให้ rubber duck ตอนสี่ทุ่ม ไม่มี paid leave และคำถามเงียบๆ ที่โผล่มาในแต่ละเดือนว่าตัดสินใจถูกแล้วหรือเปล่า
ที่ว่าไม่มี layoffs ก็ถูก แต่ปัญหาคนละชุดกันทั้งหมด เลือก risk profile ที่เหมาะกับตัวเอง
Study Path ที่เป็นไปได้สำหรับปี 2026
ไม่ใช่ลิสต์หนังสือสิบเล่มให้ไปไล่อ่าน นี่คือสิ่งที่จะให้ความสำคัญก่อนถ้ามีเวลาวันละหนึ่งชั่วโมง ขึ้นอยู่กับว่าตอนนี้อยู่จุดไหน
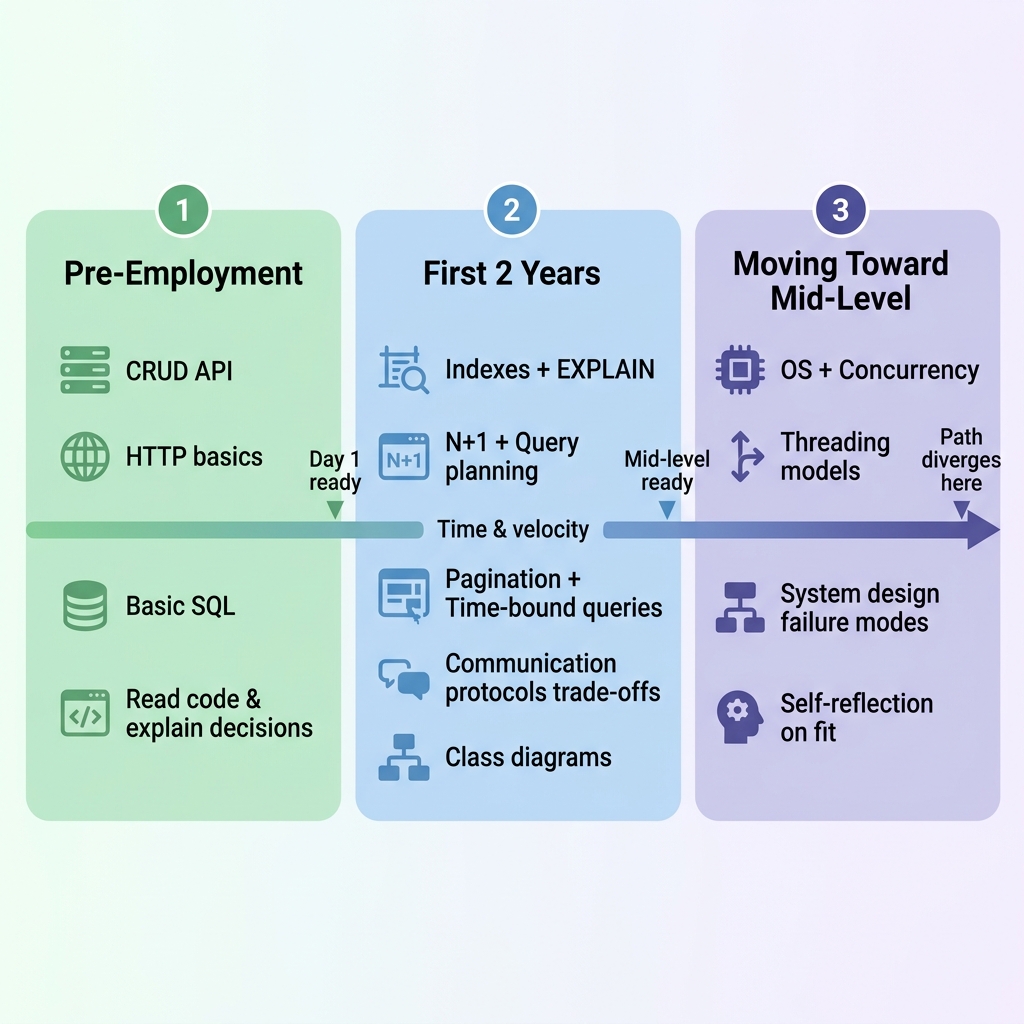
ถ้ากำลังเตรียมตัวสำหรับงานแรก (pre-employment):
มุ่งไปที่การถึง floor ไม่ใช่ ceiling
ลองสร้างบางอย่าง — basic API ที่มี database อยู่เบื้องหลัง ทำให้มัน CRUD ได้
แต่แบบฝึกหัดที่สำคัญกว่าไม่ใช่การทำให้มันรันได้ มันคือการอธิบายทุกการตัดสินใจในนั้นให้ได้
- ทำไม create endpoint ถึง return 201 ไม่ใช่ 200?
- ทำไมถึง structure table นี้ด้วย columns เหล่านี้?
- ทำไม route นี้ถึงเป็น POST ไม่ใช่ PUT?
- ทำไม query นี้ถึงเป็นแบบนี้?
ถ้าใครถามใน code review หรือ design discussion และตอบได้แค่ มันทำงานได้ หรือ copy มาจาก tutorial — นั่นคือช่องว่างที่เราไปเติมเต็มได้
ช่องว่างนั้นมองเห็นได้ทันทีสำหรับ engineers ที่กำลัง interview หรือ onboard — เคยเป็นแบบนั้นด้วยตัวเอง กว่าจะตบตีมาจนปัจจุบันได้ (แม้ว่าตอนสัมจะมีหลง ๆ ลืม ๆ ไปบ้างก็เถอะ 😂)
Engineer ทุกวันนี้ไม่ได้แค่ implement พวกเขาอธิบาย reasoning ได้ว่าทำไมถึง design แบบนี้ พิจารณาอะไรไปบ้างแล้วตัดอันไหนทิ้ง เลือก trade-off แบบไหน นั่นคือบทสนทนาที่จะได้เจอตั้งแต่วันแรก — ใน PR reviews, architecture discussions, standups ตอนระบบมีปัญหา
ไม่ต้องการ EXPLAIN, isolation levels, หรือ race conditions ก่อนเริ่ม แต่ต้องสามารถมองโค้ดของตัวเองและพูดได้ถึงการตัดสินใจในนั้น สร้างสิ่งนั้น จากนั้น practice อธิบายออกเสียง — ราวกับว่าใครบางคนเพิ่งขอให้ walk through มัน
ถ้าอยู่ในช่วงสองปีแรก:
จากที่สังเกตมา: Databases ก่อน — Return on Investment สูงที่สุด และเส้นทางที่ใกล้ production impact มากที่สุด จากนั้น networking — vocabulary ของ failure ที่ทำให้ logs และ alerts อ่านออกแทนที่จะงงกับมัน จากนั้น data structures — ไม่ใช่เพื่อ interviews แต่เพื่อจำ performance problems ได้จากรูปร่างของมัน
ถ้าตอนนี้มีเวลาสำหรับหัวข้อเดียว ให้เป็น databases
ยังเริ่ม sketch class diagrams ด้วย เลือก module ใน codebase แล้ววาด relationships ระหว่าง main classes ออกมา ไม่จำเป็นต้องมี tool — กระดาษหรือ whiteboard ก็ได้ จุดสำคัญคือการสร้างนิสัยของการคิดในแง่ relationships ไม่ใช่แค่ใน code
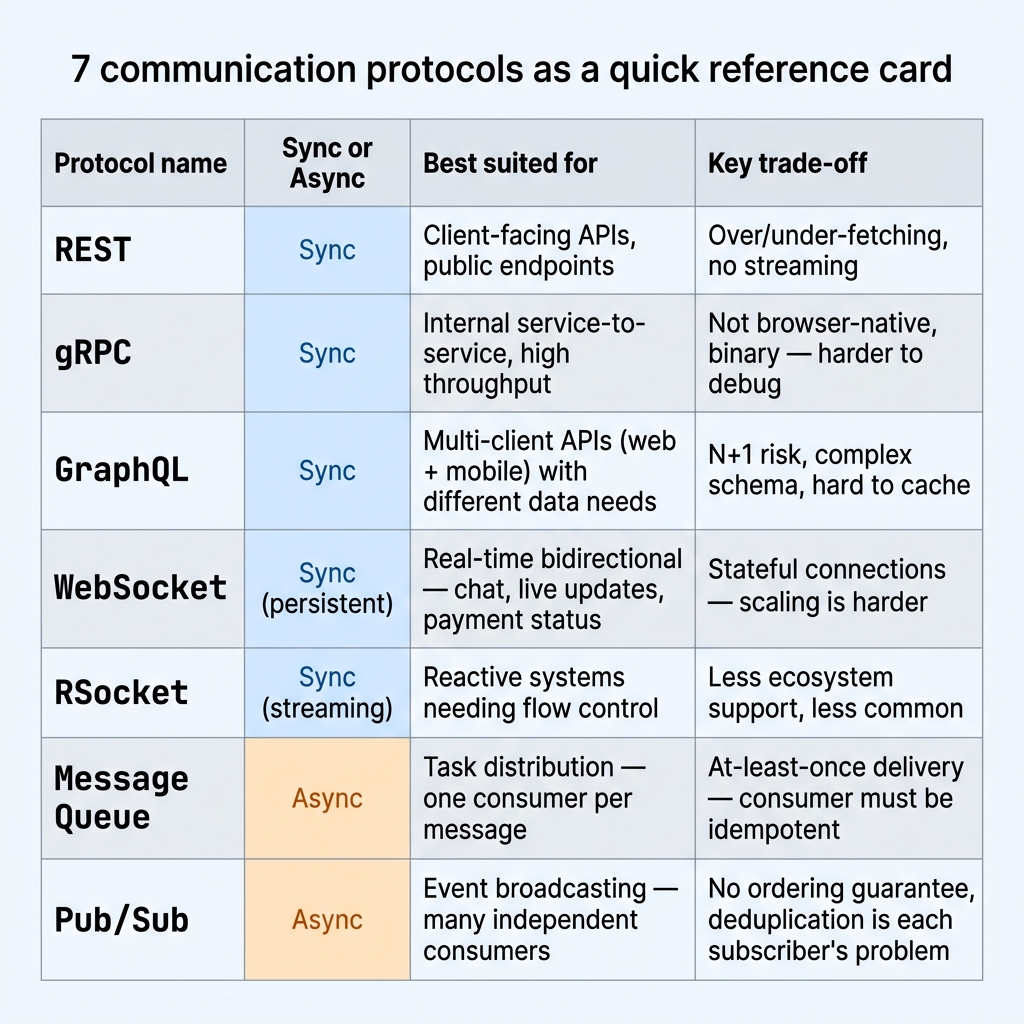
Communication patterns — landscape ของ trade-offs
ก่อนสิ้นสุดสองปีแรก ควรมีภาพของวิธีที่ services สื่อสารกัน ครอบทั้ง sync และ async landscape ที่กว้างกว่าแค่ HTTP ที่สำคัญกว่านั้น ควรสามารถ reason ได้ว่าทำไมทีมถึงเลือก approach หนึ่งแทนอีกอัน และจะเปลี่ยนอะไรถ้าไม่ได้เลือก
การแบ่งพื้นฐาน:
flowchart TD Q["How should services communicate?"] --> SYNC["Synchronous caller waits for response"] Q --> ASYNC["Asynchronous caller sends and moves on"] SYNC --> CF["Client-facing API REST · GraphQL"] SYNC --> IS["Internal service-to-service gRPC"] SYNC --> RT["Real-time bidirectional WebSocket · RSocket"] ASYNC --> ONCE["Each message consumed once Message Queue"] ASYNC --> MANY["Event fans out to many subscribers Pub/Sub"]
REST เป็น default — stateless, text-based, ใช้ได้แทบทุกที่, debug ง่าย เหมาะกับ client-facing API ส่วนใหญ่ ข้อจำกัด: ไม่มี streaming ในตัว และ client มัก over-fetch หรือ under-fetch
gRPC เป็น binary protocol บน HTTP/2 ใช้ Protocol Buffers เป็น contract เร็วกว่า REST มากสำหรับ high-throughput internal call และ strongly typed — contract change กลายเป็น compile error ทันที ใช้ใน browser โดยตรงไม่ได้ ต้องผ่าน proxy debug ยากกว่า REST และ overkill สำหรับ client-facing work ส่วนใหญ่
GraphQL ให้ client ระบุได้ว่าต้องการข้อมูลอะไร แก้ปัญหา over-fetching สำหรับ API ที่ต้องรองรับหลาย client (web, mobile) Trade-off: ฝั่ง server เสี่ยง N+1 ถ้าไม่มี dataloader, cache ยากกว่า REST, และความซับซ้อนย้ายไปอยู่ที่ schema design
WebSocket เปิด connection แบบ bidirectional ค้างไว้ตลอด เหมาะกับ real-time use case — payment status update, live dashboard, chat Trade-off: connection ที่ stateful ทำให้ horizontal scaling ยากขึ้น ต้องใช้ sticky session หรือ shared pub/sub layer คั่นไว้เบื้องหลัง
RSocket เป็น reactive streams protocol รองรับหลาย interaction model — request/response, fire-and-forget, request/stream, channel เจอน้อยกว่า gRPC แต่มีประโยชน์เมื่อต้องการ flow control หรือ streaming ที่อยู่ใน protocol เอง
Message Queue (Kafka, RabbitMQ, SQS): message แต่ละชิ้นถูก consume ครั้งเดียวโดย consumer หนึ่งราย เหมาะกับ task distribution — process payment, send email, resize image Trade-off: at-least-once delivery แปลว่า consumer ต้องเขียนให้ idempotent
Pub/Sub (SNS, Redis Pub/Sub, Kafka topics ที่มีหลาย consumer group): event หนึ่งก้อนกระจายไปถึง subscriber หลายรายที่แยกอิสระจากกัน เหมาะกับ broadcasting — event transaction completed กระจายไปทั้ง analytics, fraud detection, และ notification พร้อมกัน Trade-off: ไม่การันตี processing order ระหว่าง subscriber และ deduplication ยากขึ้น
การคิดที่อยากให้ติดตัวไม่ใช่ว่าแต่ละ technology ทำอะไรได้บ้าง มันคือคำถามว่าถ้าเลือกอีกแบบ อะไรจะพังหรือยากขึ้น:
- REST → gRPC สำหรับ internal service? เร็วขึ้นและ type-safe แต่ตอนนี้ต้องการ protobuf contracts และการ debug ยากขึ้น คุ้มค่าที่ call frequency สูง น่าจะไม่คุ้มกับ low-traffic internal admin API
- Synchronous REST call → message queue? Decouple services และรับ burst load ไว้ได้ แต่ caller ไม่รู้ทันทีว่าสำเร็จไหม Eventual consistency ยอมรับได้ที่นี่ไหม? User ต้องการ real-time confirmation ไหม?
- Message queue → pub/sub? ตอนนี้หลาย services react ต่อ event เดียวกันอิสระ — ดีสำหรับ fan-out แต่แต่ละ subscriber process ทุก message และ deduplication กลายเป็นปัญหาของแต่ละ subscriber
- REST polling → WebSocket? Real-time push แทน client-initiated checks แต่มี stateful connections เข้ามา Server รองรับ concurrent connections ได้กี่อัน? เกิดอะไรขึ้นเมื่อ restart?
คำถามไม่ใช่ว่า technology ไหนดีที่สุด มันคือการคิดว่า: ด้วย constraints เหล่านี้ trade-offs ไหนยอมรับได้?
ถ้ากำลังขยับสู่ mid-level (2–5 ปี):
Operating systems และ concurrency นี่คือช่องว่างที่เห็นบ่อยที่สุดในระดับนี้ เข้าใจ threading models, memory management, และ file descriptors
System design — แบบ failure mode สำหรับ external dependency ทุกอย่างใน current system trace ผ่าน failure modes นี่คือ practice ที่ทำได้ที่ทำงานกับ systems ที่มีอยู่
More than that:
ขอออกตัวก่อน: ด้วยประสบการณ์ 7 ปี ยังให้ map ที่แน่นอนสำหรับเส้นทางที่อยู่ถัดจากนี้ไม่ได้ — paths แยกออกมากเกินไประหว่าง staff engineering, architecture, management, หรือการสร้างบางอย่างของตัวเอง แต่สิ่งที่บอกได้จากที่ผ่านมาคือ starting point
พอถึงระดับนี้ self-reflection กลายเป็นเครื่องมือที่เชื่อถือได้ที่สุด — ปัญหาแบบไหนที่ดึงดูดเรา งานแบบไหนที่ทำแล้วเหนื่อยซ้ำๆ เลือก direction ที่เหมาะแล้วเติบโตต่อจากจุดนั้น และเมื่อมันเริ่มไม่เหมาะแล้ว ลองย้อนกลับไปดูสิ่งที่เคยรู้สึกว่าน่าสนใจก่อนหน้านี้แต่ยังไม่มีเวลา explore เต็มที่ Pivot ที่ดีส่วนใหญ่ไม่ได้มาแบบสุ่ม ๆ มักเป็นสิ่งที่เคยสังเกตเห็นและเก็บไว้นานแล้ว — อย่างน้อยก็เป็นแบบนั้นสำหรับตัวเอง
ปิดท้าย
Fundamentals ไม่ใช่ trivia gatekeeping ที่ interview culture ทำให้ดูเป็น มันคือสิ่งที่ทำให้คิดเกี่ยวกับ code ได้อย่างมีเหตุผล — ไม่ว่าจะกำลัง debug production incident, review PR ของเพื่อนร่วมงาน, หรือ evaluate สิ่งที่ AI สร้างขึ้นมาในสามวินาที
Engineer ที่จะเติบโตได้เร็วที่สุดในสองสามปีข้างหน้า — จากที่สังเกต — ไม่ใช่คนที่ prompt เก่งที่สุด มันคือคนที่ prompt ได้ดีและ evaluate ได้ถูก และการ evaluate สร้างขึ้นบนการเข้าใจสิ่งที่กำลังมอง
ไม่จำเป็นต้องรู้ทุกอย่าง ต้องรู้พอที่จะถามคำถามที่ถูกต้องเกี่ยวกับ code ที่กำลังดูอยู่
ลองชี้ให้ได้หนึ่งอย่างที่อ่านบทความนี้แล้วยังอธิบายไม่ได้ชัด ไม่เอาหัวข้อกว้างๆ ขอเป็น behavior เจาะจง: ทำไม pagination ถึงช้าเมื่อผ่าน page 100, ความต่างระหว่าง 401 กับ 403 หมายความว่าอะไรใน auth flow ของ system ตัวเอง, เกิดอะไรขึ้นกับ transaction ที่กำลังประมวลผลอยู่เมื่อ payment gateway call หมด timeout เอาช่องว่างนั้นไปปิดบน codebase ที่ใช้งานอยู่ในสัปดาห์นี้ — นี่คือสิ่งที่ทำแล้วได้ผล ความเข้าใจสะสมจากช่วงเวลาที่ตั้งใจและเฉพาะเจาะจง — ไม่ใช่จาก reading lists หรือความตั้งใจที่ยังไม่ได้ลงมือ
Last Fun Fact — ภาษามาทีหลัง Fundamentals
หลังจากเดินผ่าน floor ของ entry level ทั้งหมดมาแล้ว ขั้นต่อไปคือเลือก programming language สักภาษามาใช้ แล้วอยู่กับมันไปสักระยะ แต่ลองสังเกตลำดับดู — ภาษาโปรแกรมมาทีหลัง fundamentals ลำดับนี้ตั้งใจจัดเอาไว้แบบนี้ พอเลือกภาษาแล้ว ส่วน implementation จะต่างกันตาม paradigm ของแต่ละภาษา (object-oriented, functional, systems-level) แต่ fundamentals ที่อยู่ข้างใต้ยังเป็นเรื่องเดียวกันหมดไม่ว่าจะเขียนด้วยภาษาไหน
เขียนจากประสบการณ์ทำงานบน backend systems — ที่ผ่านมาส่วนใหญ่ปัญหาที่น่าสนใจเป็นเรื่อง database, networking, หรือ concurrency — ไม่ใช่ algorithm puzzles
ปล. — ผมเองก็เปิดรับงาน consult / advisory ด้าน backend system แนว ๆ นี้อยู่บ้างนะ ถ้าคิดว่าพอจะช่วยทีมได้ แวะมาดูบริการกันได้เลย.