
How Netflix Uses Java — 2026 Edition: My Notes
Introduction
I sat down to watch Paul Bakker’s talk “How Netflix Uses Java — 2026 Edition” the other day. Paul works on the Java Platform team at Netflix and is also the author of the DGS Framework, so this talk is basically a tour of the stack from someone who builds the paved road, not someone who just rides on it.
Original video: How Netflix Uses Java — 2026 Edition
This post is my notes, walked through in the same order as the talk. I am a Java/Spring Boot backend engineer myself, so a lot of what Paul covered overlapped with things I think about at work — upgrade pain, GC tuning, virtual threads, and now Gen AI inside Java services. I wanted to write it down while it was still fresh.
One thing worth flagging upfront: Paul has been giving this “How Netflix Uses Java” talk annually, so the 2026 edition is really an update on where things landed since the 2025 version. A few items that were experiments or open problems last year — Generational ZGC, virtual threads, the reactive debate — have now resolved into defaults. I will call out those shifts as we go.
Java is slow? Not at this scale
Paul opens by pushing back on the “Java is slow” meme that keeps floating around social media. His point is simple: at Netflix’s scale, the JVM is still the most practical backend platform. It is not a legacy pick that nobody wants to touch — it is the platform they keep doubling down on because the trade-offs make sense.
That framing matters because the rest of the talk is essentially evidence for that position. Architecture choices, upgrade strategy, GC tuning, and Gen AI integration — all of them are easier to understand once you accept that Java is the default, not the fallback.
Two very different Netflix backends
The first thing Paul makes clear is that “Netflix backend” is actually two different worlds under the same roof.
The Streaming backend is the one most people imagine. It powers the consumer app — browsing, recommendations, playback controls. It has to handle extreme RPS, multi-region low-latency requirements, deep microservice fan-outs, and mostly non-relational datastores.
The Studio and internal enterprise apps are a completely different beast. Netflix runs one of the largest movie studio operations on the planet, and all of that needs software too. These systems look much more traditional: lower RPS, single-region deployments, standard relational databases, CRUD-heavy flows.
Both sides run Java. But the constraints are different, so the engineering trade-offs are different too. I like that Paul names this split upfront — it stops the audience from assuming everything at Netflix has to be Google-scale.
The federated GraphQL gateway
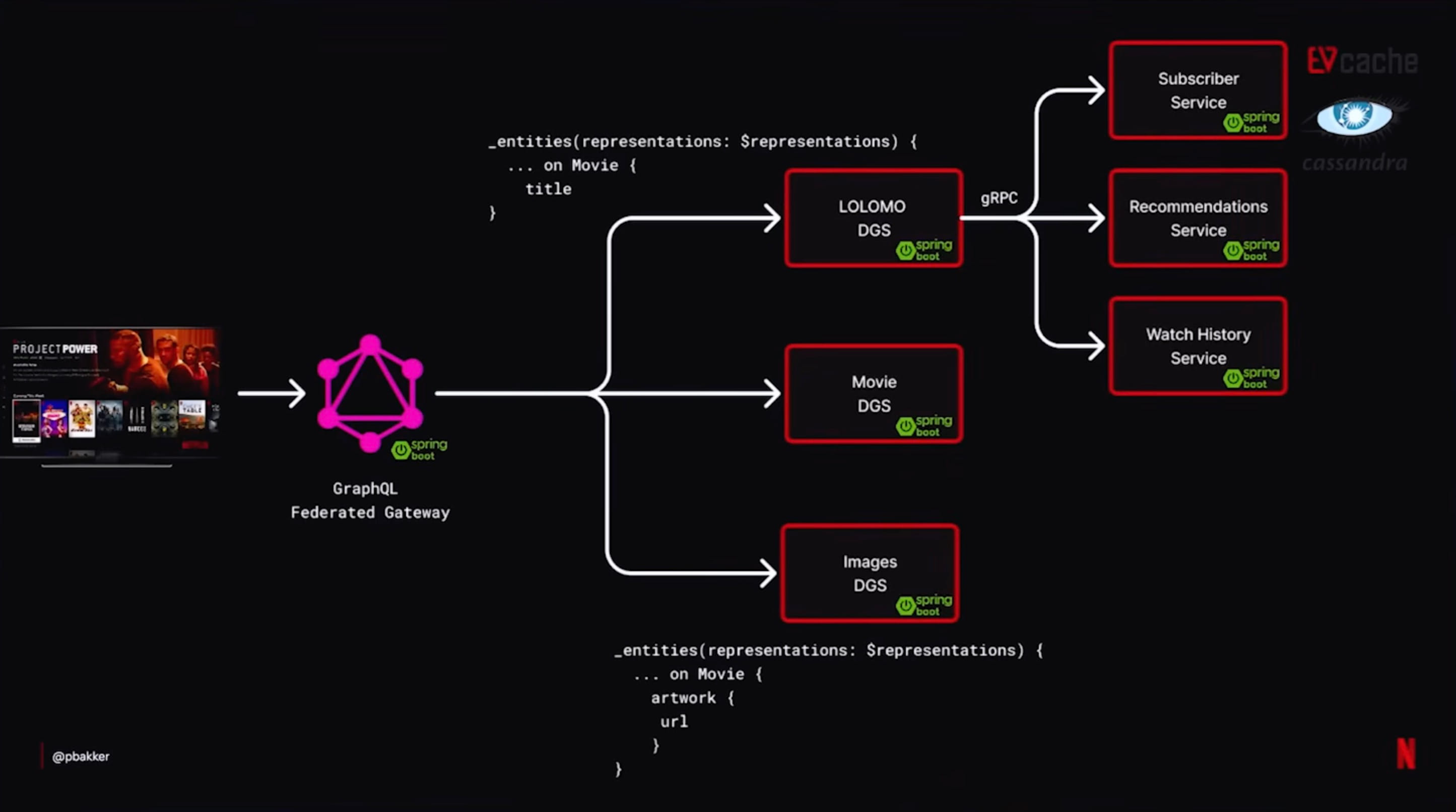
Both architectures sit behind a Federated GraphQL gateway. A single client request hits the gateway, gets split into fragments, and each fragment is routed to a targeted Domain Graph Service (DGS).
In the slide above you can see how one request for a Movie entity fans out — the title field goes to the LOLOMO DGS, the artwork field goes to the Images DGS, and further gRPC calls go down to services like Subscriber, Recommendations, and Watch History. Each leaf is its own Spring Boot service.
This is the DGS pattern Netflix open-sourced a few years ago. The interesting part in 2026 is how deeply it is embedded — it is no longer a frontend experiment, it is the main shape of the platform.
Below the gateway, the DGS nodes and every deeper service talk to each other via gRPC. GraphQL is reserved for the client-facing edge where schema flexibility matters. gRPC is used for server-to-server where latency and method execution matter more than flexibility.
Discovery vs. Playback (Open Connect)
One distinction I had not thought about before: browsing the UI uses the cloud architecture, but the moment you hit Play, the system shifts to Open Connect — Netflix’s physical CDN hardware sitting inside ISP racks.
The video bits come from that hardware, not from the cloud. But the control plane that manages the Open Connect network is also Java and Spring Boot. So even the hardware delivery layer has a JVM brain behind it.
Why Java?

Paul sums up the language choice in one line: Java is the best trade-off between runtime performance, developer productivity, and maintainability.
Runtime performance is solid for typical backend work, and developer productivity stays high once you factor in ecosystem, tooling, hiring, and long-term code health. It is boring in the good way — the kind of boring that lets thousands of services be maintained by thousands of engineers without constant surprises.

Of course it is not everything. UIs use platform-native languages — optimized JS for TV, Swift for iOS, Kotlin for Android. Low-level Kubernetes sidecars use Go. Data science and model training live in Python. But for almost everything else on the server side, Java wins by default.
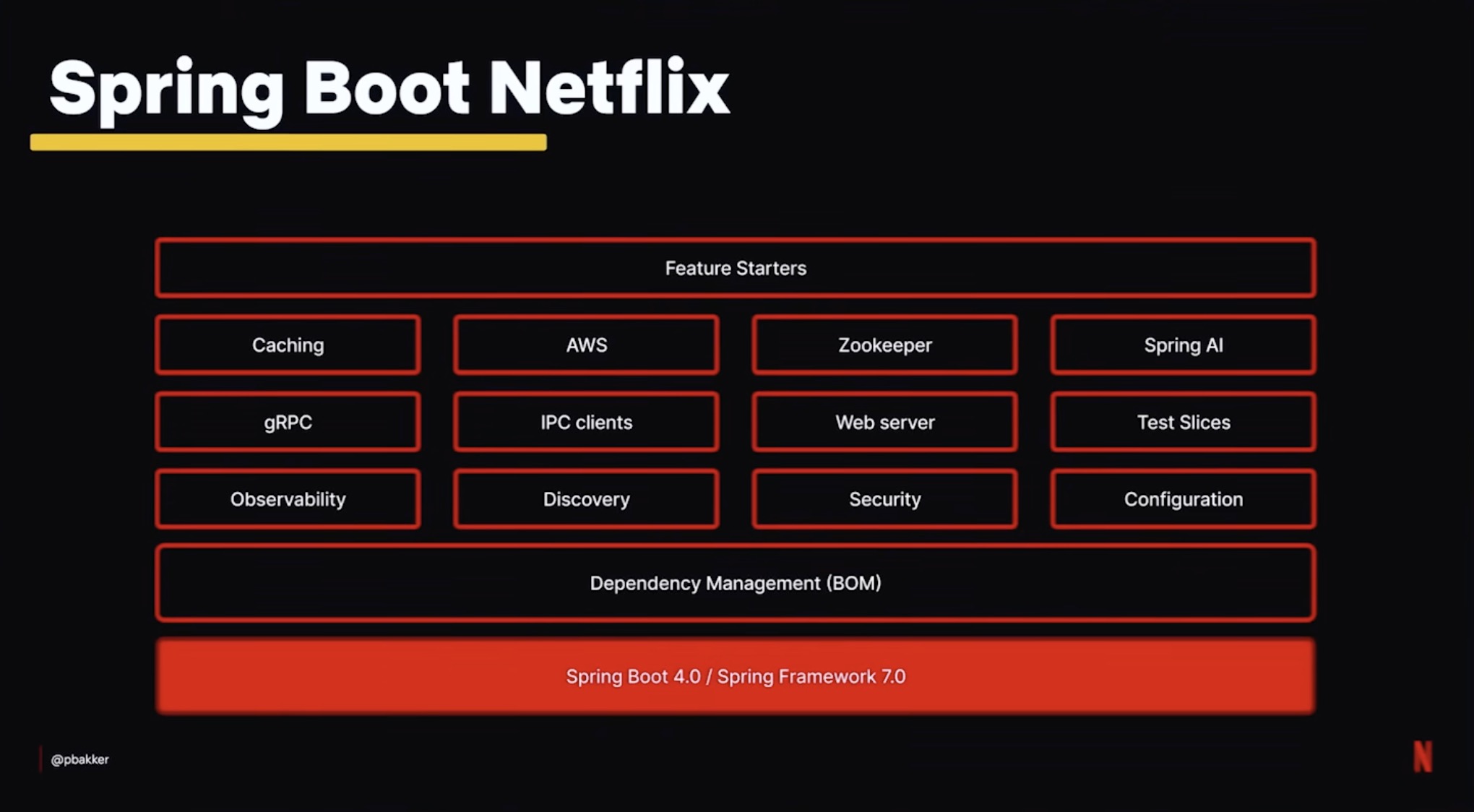
Spring Boot as the “paved road”
Spring Boot is the foundation underneath 3,000–4,000 backend applications at Netflix. That number alone tells you why the platform team cares so much about getting it right — any friction they add hits thousands of services at once.
The approach is custom Autoconfiguration modules that map directly onto open-source Spring paradigms. Internal security, dynamic configuration, tracing, gRPC — all of them are wired in the Spring-native way, so developers do not learn a parallel Netflix-only universe. They learn Spring Boot, and the Netflix bits appear as starters.
This is worth pausing on. A lot of big companies build a parallel framework on top of Spring and end up with a dialect nobody outside the company can read. Netflix avoided that trap by leaning into Spring’s own extension points. New engineers onboard faster, and the platform team stays closer to upstream.
On testing, Paul highlights @SpringBootTest paired with targeted slice annotations like @EnableDgsTest. You get an integration-level test that only bootstraps the layers you actually need, so you are not loading the entire app context for a single controller test. I have felt this pain in smaller codebases — at Netflix scale, skipping that optimization would make tests unusable.
Version migrations at 4,000-app scale
One part of the talk I enjoyed most was the honest look at upgrade pain. When Spring Boot moved from 2 to 3, the whole ecosystem had to shift from javax to jakarta. This created a chicken-and-egg problem: apps could not upgrade until their libraries upgraded, and libraries could not upgrade without breaking apps that had not moved yet.
Netflix’s solution was a custom Gradle transform that manipulates bytecode at dependency resolution time, combined with OpenRewrite and Gradle Lint. The transform essentially rewrote javax references to jakarta on the fly, so libraries could move at their own pace without blocking consumers.

For the Spring Boot 3 to 4 upgrade, they took a very different approach: Claude Code running headless as a batch job. The LLM runs sequential upgrade prompts on each repository, with checkpointing so platform engineers can inspect failures and resume from a known-good state. The interesting trade-off here is that Netflix consciously picked an LLM over deterministic OpenRewrite AST rules — LLMs are cheaper to author and more resilient to weird corner cases that would take forever to encode as AST patterns.
The philosophy underneath all of this is: rip off the band-aid early. Delaying framework upgrades creates technical debt that eventually blocks you from adopting new libraries like Spring AI. Keeping velocity means not letting the version gap grow.
Protocol standards: GraphQL, gRPC, and REST is dead

Paul devotes a short section to clarifying which protocol Netflix uses where, and the slide is delightfully blunt — REST gets a tombstone.
- GraphQL is used at the client edge for flexible, client-driven data fetching. The DGS framework is the implementation. Think in terms of data, not methods.
- gRPC is used strictly for server-to-server backend communication where latency and method execution matter more than schema flexibility. Think in terms of methods, not data.
- REST is effectively deprecated for new primary development at Netflix.
I find the REST decision interesting. REST is not bad — it is just that once you have a federated GraphQL edge for clients and gRPC for service-to-service, the niche where REST is the right tool shrinks to almost nothing. New services skip REST entirely.
Garbage Collection: Generational ZGC
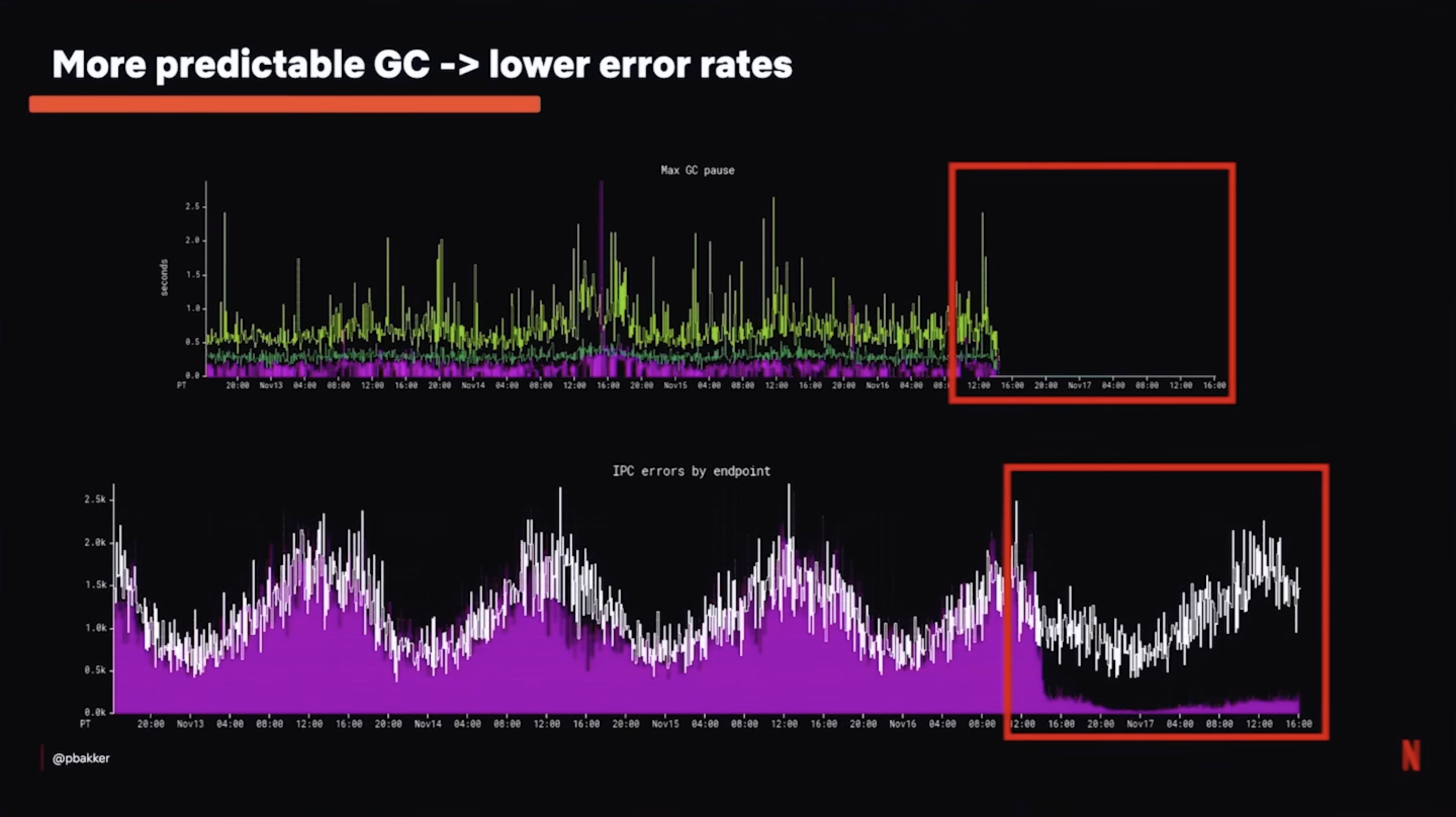
G1GC used to cause up to 1.5-second “stop the world” pauses on Netflix services. That sounds survivable until you remember that Netflix runs aggressive IPC timeouts — if a service pauses for 1.5 seconds, upstream callers give up, retry, and suddenly the whole cluster is under retry storm load. One pause becomes a fan-out incident.
Switching to Generational ZGC eliminated those pauses. The trade-off is that ZGC burns more baseline CPU on background collection work. But removing the timeout errors and the resulting retry traffic actually reduced overall cluster load and lowered functional latency. The graph in the slide above shows the drop in max GC pause time alongside the drop in IPC errors per endpoint.
Generational ZGC is now the default GC for Netflix microservices. That is a strong endorsement considering how conservative big platform teams usually are with runtime switches.
Virtual Threads on JDK 25
Netflix tried virtual threads early on JDK 21 and had to roll back. The issue was thread-pinning deadlocks — certain native or synchronized operations would pin a carrier thread, and under load the application would deadlock.
Pinning was resolved in JDK 25, and Netflix is now injecting virtual threads automatically at the framework level — Tomcat connectors, thread pools inside starters, and similar. Applications get the concurrency scaling benefit for free, without developers having to opt in or change code.
The unglamorous detail is context propagation. StructuredTaskScope does not copy ThreadLocal values into newly forked virtual threads, and ThreadLocal is where tracing, security context, and observability metadata usually live. The modern replacement, ScopedValues, is still missing framework support across the stack.
Netflix’s workaround is a custom ThreadFactory injected into the concurrency scope, which runs Micrometer context propagation manually when a virtual thread is created. It is the kind of fix you only discover by running this in production and watching traces go blank. Worth remembering if you are rolling out virtual threads in your own stack.
Newer Java is replacing the role reactive used to play
This did not get a dedicated slide in the 2026 talk, but it is worth pulling out because it ties the virtual threads story to a larger trend in the Java world. In the 2025 edition, Netflix had talked about RxJava and WebFlux as an experiment that did not work out for them — powerful in theory, but the debugging complexity and cognitive overhead were not worth it at their scale. The stated direction was that virtual threads plus structured concurrency would take over the role reactive was filling.
A year later, that direction looks right at least within the Netflix context. They have standardized on WebMVC, and the imperative model with virtual threads gives them the concurrency benefits that originally pushed teams toward reactive — without the stack traces that make you want to quit your job.
I want to be careful not to over-generalize this. Reactive is not dead everywhere — there are still systems where backpressure semantics and stream composition are exactly what you need, and WebFlux is the right answer for them. But the broader pattern is real: a lot of teams reached for reactive because Java did not have a good concurrency model, and newer JDK versions are finally closing that gap. If your reason for picking reactive was “I need to handle a lot of concurrent IO without blocking platform threads,” virtual threads now give you that without the cognitive tax. Worth re-examining the assumption next time you start a new service.
Gen AI and Agentic Workflows in Java

The last third of the talk was about Gen AI, and this is where it got interesting. Netflix is moving from basic LLM chat completions toward structured Agentic Workflows written in Java microservices.
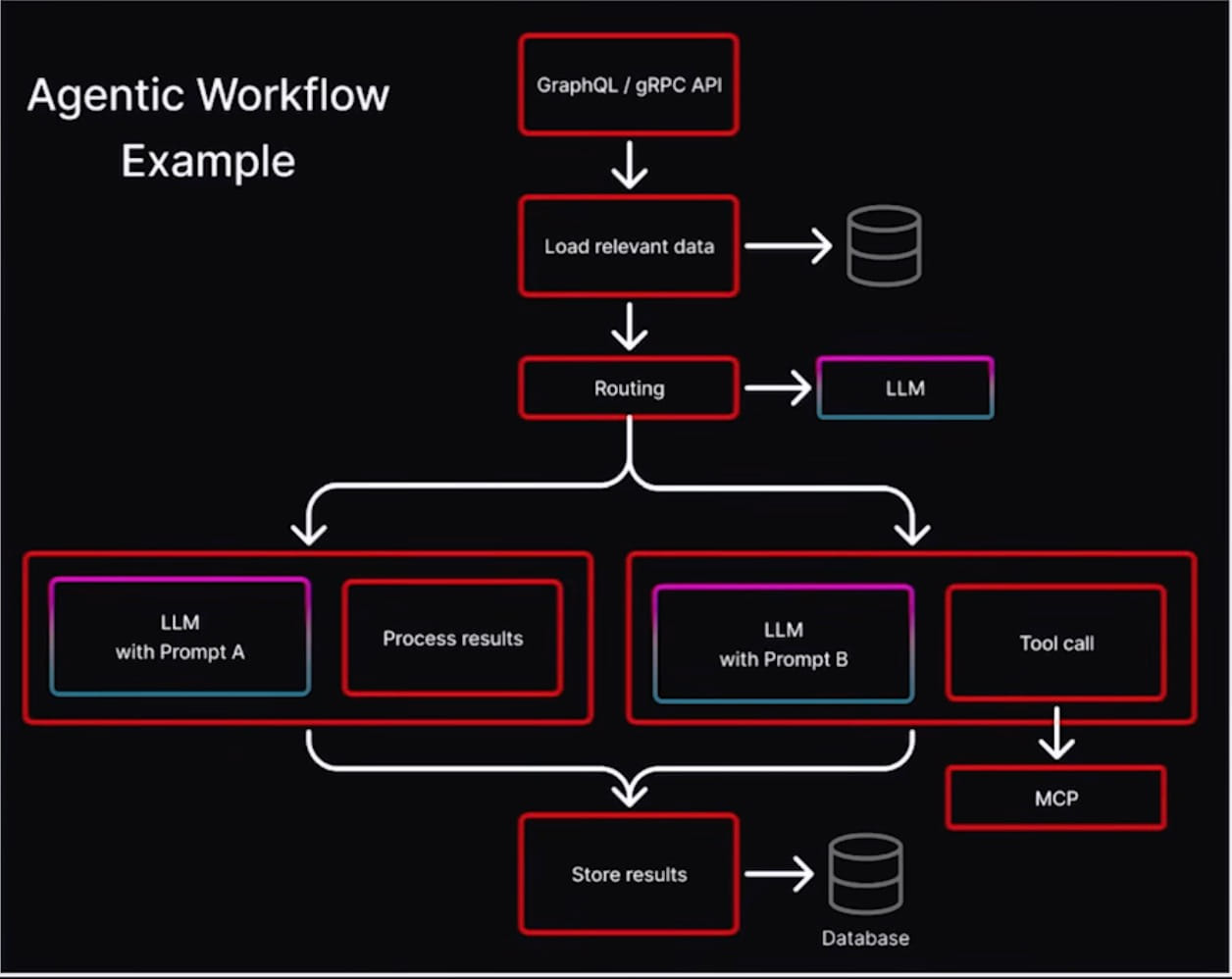
The model is: your application keeps deterministic control of the overall flow — routing, loading data, storing results — while specific nodes inside that flow call out to an LLM for reasoning. You do not hand the whole program over to a model. You hand specific decisions over.
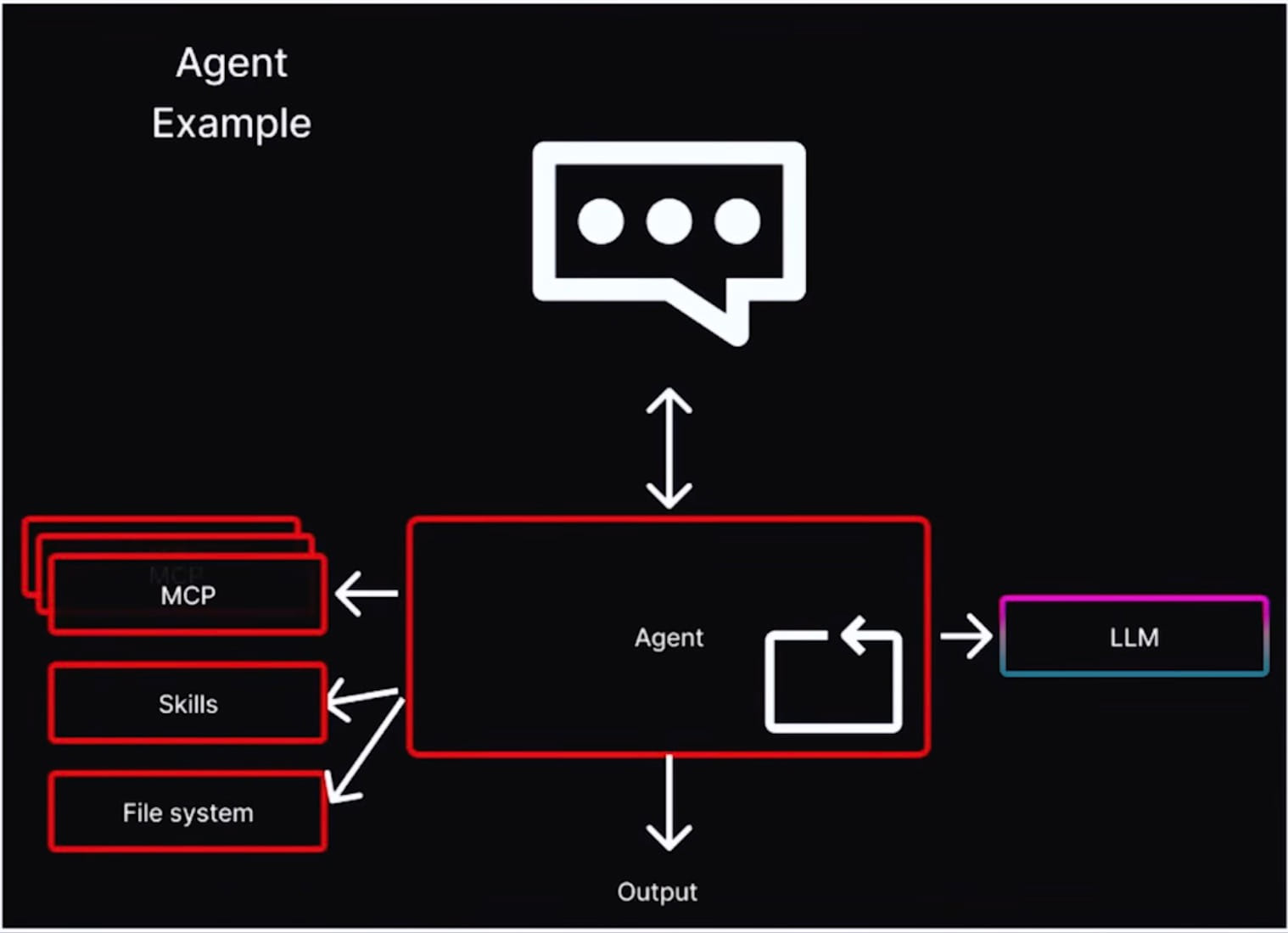
Agents in this picture are components with access to MCP tools, skills, a file system, and an LLM, wrapped inside a deterministic application loop. It looks more like traditional service design than “chat with your app.”

On language choice, Paul’s argument is that Java has caught up. Two years ago, most Gen AI libraries were Python-only, so using Python was the pragmatic choice. Today, Spring AI and LangChain4j have reached rough parity with the Python ecosystem. Given the JVM’s execution speed and the massive existing Java talent pool at places like Netflix, Java is now a very strong runtime for productionizing LLM workflows.
One concrete example Paul shared: an internal agent that analyzes Spring application startup performance. Instead of dumping raw profiling output on the developer, the LLM reads trace data, pulls the relevant internal library source, and writes actionable refactoring recommendations. That is the shape of the value — using the LLM to close the gap between “here is some data” and “here is what to change.”
What I take away from this talk
A few things stuck with me after the video ended:
Boring, well-chosen defaults scale. Netflix’s choice of Spring Boot as the paved road, built with Spring-native extension points instead of a dialect, is the reason 4,000 apps can coexist without chaos. It is not flashy but it compounds.
Upgrade velocity is a product decision. Rip off the band-aid early. If you let framework versions drift, you eventually cannot adopt the libraries you need — Spring AI being the current example. The Claude Code batch-upgrade pipeline is a glimpse at where infrastructure work is heading.
GC choice is a reliability lever. Generational ZGC is the clearest win in the talk — eliminating pause-driven timeouts dropped retry loads and made the whole cluster calmer. Worth testing on your own services if you are still on G1GC.
Virtual threads are ready, but mind the plumbing. Context propagation is the thing that bites you. If tracing and security context rely on ThreadLocal, roll out carefully and watch for blank spans before you celebrate.
Newer Java is replacing the role reactive used to play. Virtual threads plus structured concurrency now cover most of the use cases that originally drove teams to WebFlux/RxJava. Reactive is still right in some places, but if your reason for picking it was “I need non-blocking concurrency on the JVM,” that reason has weakened a lot.
Agentic workflows belong in Java services. Keeping the application loop deterministic and only calling the LLM for specific nodes feels much more operable than handing everything to an agent. And with Spring AI and LangChain4j, you no longer have to leave the JVM to do it.
My action item from this talk: I want to do a hands-on exploration of building an agentic workflow in Java (Spring AI, LangChain4j, or ADK Java) instead of Python. The JVM will use more memory than a Python equivalent, but for a long-running production service the throughput and latency should technically be better. This is on my list for an upcoming side project.