
สรุป How Netflix Uses Java — 2026 Edition
Introduction
ผมไปเจอ talk ของ Paul Bakker ชื่อ How Netflix Uses Java — 2026 Edition ใน YouTube
Paul อยู่ทีม Java Platform ของ Netflix และเป็นคนเขียน DGS Framework เอง ดู talk นี้ก็เหมือนเดินตาม tour tech stack ของ Netflix กับคนที่สร้าง paved road ให้คนอื่นใช้ ไม่ใช่คนที่แค่ใช้งานอีกที
Video ต้นฉบับ: How Netflix Uses Java — 2026 Edition
โพสต์นี้เป็นบันทึกของผมเองตามลำดับที่ Paul เล่า ผมเป็น backend engineer สาย Java/Spring Boot อยู่แล้ว หลายเรื่องที่เขาพูดก็เป็นสิ่งที่ผมต้องเจอในงานเหมือนกัน ทั้งเรื่อง upgrade pain, GC tuning, virtual thread และล่าสุดคือเรื่อง Gen AI ที่เข้ามาอยู่ใน service ของ Java แล้ว เลยอยากเขียนไว้อ่านเองด้วย
มีเรื่องที่อยากบอกไว้ก่อนอ่านสักนิด Paul ทำ talk ชุดนี้เป็นประจำทุกปี ฉบับ 2026 เลยเป็นการ update ต่อจากปี 2025 ที่เขาพูดไว้ หลายเรื่องที่ปีก่อนยังเป็น experiment หรือยังแก้ไม่เสร็จ เช่น Generational ZGC, virtual thread, เรื่อง reactive ปีนี้กลายเป็น default ของทีมหมดแล้ว ผมจะชี้ให้ดูตอนเล่าแต่ละหัวข้อ
Java is slow? Not at this scale
Paul เปิด talk มาด้วยการโต้ meme ที่ลอยใน social media ว่า Java ช้า ประเด็นของเขาคือ ที่ scale ของ Netflix JVM ยังเป็น backend platform ที่ practical ที่สุดอยู่ มันไม่ใช่ legacy ที่ไม่มีใครอยากแตะ แต่เป็น platform ที่ทีมเลือกใช้ต่อเพราะ trade-off มันลงตัวที่สุดแล้ว
การเปิดแบบนี้ตั้ง tone ได้ดี เพราะเนื้อหาที่เหลือทั้ง talk ก็เป็นหลักฐานสนับสนุนจุดนี้ ไม่ว่าจะเป็น architecture, upgrade strategy, GC tuning หรือ Gen AI พอเรายอมรับว่า Java ยังเป็น default ของ Netflix อยู่ เรื่องที่เหลือก็เข้าใจง่ายขึ้นเยอะ
Two very different Netflix backends
เรื่องแรกที่ Paul อธิบายคือ backend ของ Netflix ไม่ได้เป็นก้อนเดียว แต่เป็น 2 โลกที่อยู่ใต้หลังคาเดียวกัน
Streaming backend คือฝั่งที่คนทั่วไปนึกถึงเวลาได้ยินคำว่า Netflix ทำงานให้ app ของ consumer ทั้งการ browse, recommendation และ playback controls ตัวนี้ต้องรับ RPS สูงมาก, latency ต่ำข้าม region, microservice fan-out ลึก และใช้ non-relational datastore เป็นหลัก
อีกฝั่งคือ Studio และ internal enterprise app ฝั่งนี้เป็นคนละโลกเลย Netflix มีธุรกิจ movie studio ของตัวเองที่ใหญ่ระดับโลก และทั้งหมดต้องมี software รองรับ แต่ระบบฝั่งนี้หน้าตาแบบ traditional กว่ามาก RPS ต่ำกว่า deploy แค่ region เดียว ใช้ relational database ปกติ flow ส่วนใหญ่เป็น CRUD
ทั้ง 2 ฝั่งใช้ Java หมด แต่ constraint ต่างกัน trade-off ก็เลยต่างกันด้วย Paul พูดเรื่องนี้ตั้งแต่ต้น talk เลย ซึ่งช่วยให้คนฟังไม่ assume ว่าทุกอย่างที่ Netflix ต้อง scale แบบ Google
The federated GraphQL gateway
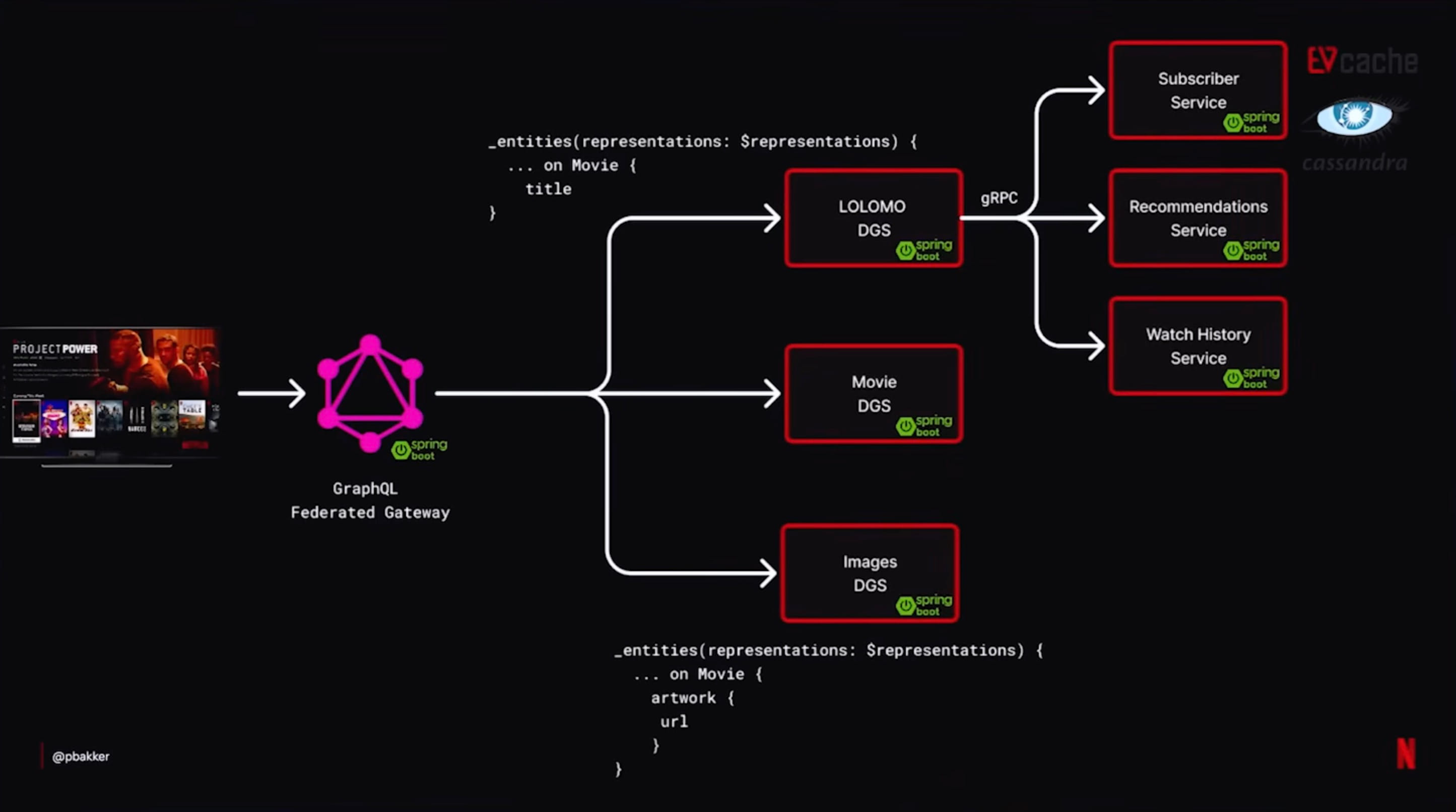
ทั้ง 2 architecture อยู่หลัง Federated GraphQL Gateway เดียวกัน request จาก client เข้ามาที่ gateway แล้วถูกแยกเป็น fragment ส่งไปให้ Domain Graph Service (DGS) ที่รับผิดชอบแต่ละส่วน
ในภาพจะเห็นว่า request เดียวของ Movie entity มันแตกออกไปยังไง field title ไปที่ LOLOMO DGS, field artwork ไปที่ Images DGS แล้วลึกลงไปอีกก็มี gRPC ยิงต่อไปที่ Subscriber, Recommendations, Watch History service แต่ละ leaf เป็น Spring Boot service ของมันเอง
ตรงนี้คือ DGS pattern ที่ Netflix open-source ไว้เมื่อหลายปีก่อน สิ่งที่เปลี่ยนไปในปี 2026 คือมันถูกฝังลึกอยู่ใน platform มาก ไม่ใช่ experiment ของทีม frontend อีกแล้ว มันเป็นโครงหลักของระบบไปแล้ว
ใต้ gateway ลงไป DGS node และ service ที่ลึกกว่านั้นคุยกันด้วย gRPC ทั้งหมด GraphQL จะถูกเก็บไว้ใช้เฉพาะ edge ที่ติดกับ client ซึ่งต้องการความยืดหยุ่นของ schema ส่วน gRPC ใช้กับ server-to-server ที่สำคัญเรื่อง latency และการ execute method มากกว่า
Discovery vs. Playback (Open Connect)
มีจุดหนึ่งที่ผมไม่เคยคิดมาก่อน คือเวลา browse UI ของ Netflix เราจะใช้ cloud architecture แต่พอกด Play ปุ๊บ ระบบจะ switch ไปที่ Open Connect ซึ่งเป็น CDN ของ Netflix ที่เป็น hardware วางอยู่ใน rack ของ ISP แต่ละประเทศเลย
bit ของวิดีโอถูกส่งมาจาก hardware ชุดนั้น ไม่ได้ยิงมาจาก cloud แต่ที่น่าสนใจคือ control plane ที่ manage network ของ Open Connect ก็ยังเป็น Java + Spring Boot อยู่ดี แม้แต่ hardware delivery layer ก็ยังมี JVM เป็นสมองอยู่ข้างหลัง
Why Java?

Paul สรุปเหตุผลในบรรทัดเดียว Java คือ trade-off ที่ดีที่สุดระหว่าง runtime performance, developer productivity, และ maintainability
runtime performance ของมันก็โอเคสำหรับงาน backend ทั่วไป และ developer productivity ก็ยังสูงอยู่เมื่อรวม ecosystem, tooling, การหา developer, และ long-term health ของ code มันคือความน่าเบื่อในแบบที่ดี น่าเบื่อแบบที่ทำให้ service หลักพันตัวถูก maintain โดย engineer หลักพันคนได้โดยไม่มี surprise ตลอดเวลา

แต่ก็ไม่ใช่ว่าทุกอย่างเป็น Java นะครับ UI ใช้ภาษา native ของแต่ละ platform เช่น JS ที่ถูก optimize สำหรับ TV, Swift สำหรับ iOS, Kotlin สำหรับ Android ส่วน Kubernetes sidecar ใช้ Go ส่วน data science กับ model training อยู่กับ Python แต่เกือบทุกอย่างฝั่ง server นั้น Java เป็น default
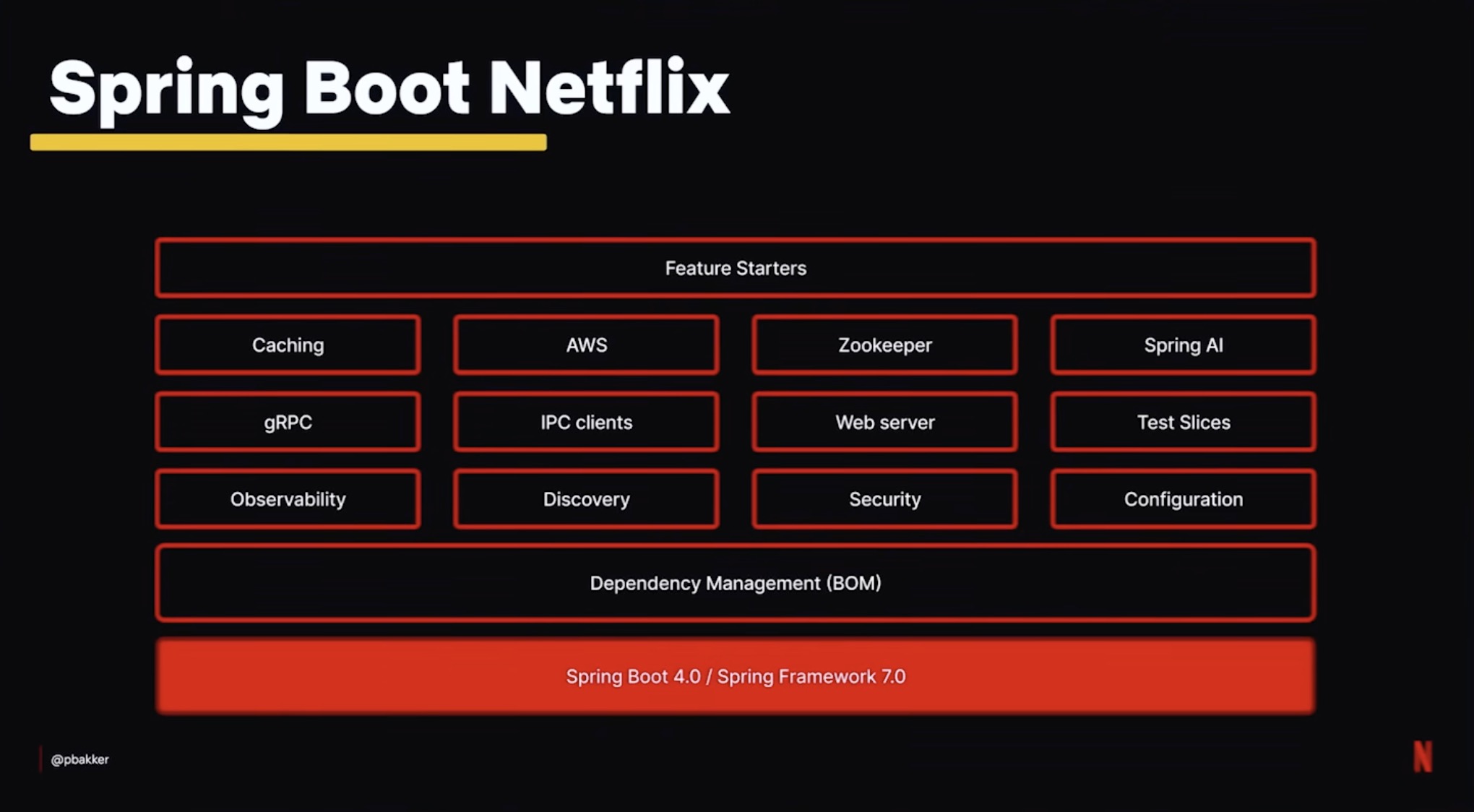
Spring Boot as the paved road
Spring Boot เป็นฐานของ backend application 3,000–4,000 ตัว ที่ Netflix พอเห็นตัวเลขนี้แล้วก็เข้าใจเลยว่าทำไมทีม platform ต้องซีเรียสกับการทำเรื่องนี้ เพราะ friction อะไรก็ตามที่ทีมเพิ่มเข้าไป จะกระทบ service หลักพันตัวในทีเดียว
สิ่งที่ทีมทำคือเขียน custom Autoconfiguration module ที่ map เข้ากับ paradigm ของ Spring open-source โดยตรง ไม่ว่าจะเป็น internal security, dynamic configuration, tracing, gRPC ทุกอย่างถูกต่อเข้ามาในแบบที่ Spring เขาใช้กันอยู่แล้ว developer ก็เลยไม่ต้องมานั่งเรียน universe แบบ Netflix-only คู่ขนาน แค่รู้ Spring Boot ปกติ แล้วของ Netflix จะโผล่มาในรูปของ starter
จุดนี้ผมว่าสำคัญมาก บริษัทใหญ่หลายที่สร้าง framework คู่ขนานบน Spring แล้วสุดท้ายกลายเป็น dialect ที่คนนอกอ่านไม่ออก Netflix เลี่ยง trap นี้ได้ด้วยการเกาะ extension point ของ Spring เอง engineer ใหม่ onboard ได้เร็วขึ้น และทีม platform ก็ไม่ drift ห่างจาก upstream
เรื่อง testing Paul พูดถึงการใช้ @SpringBootTest คู่กับ slice annotation แบบเฉพาะเจาะจงอย่าง @EnableDgsTest เพื่อโหลดเฉพาะ layer ที่จำเป็น ไม่ต้องโหลด context ทั้ง app แค่เพื่อ test controller ตัวเดียว ผมเคยเจอความช้าของ test แบบนี้ใน codebase เล็กกว่านี้ถึงจะรู้ว่าปวดหัวแค่ไหน ถ้า Netflix ไม่ optimize เรื่องนี้ test คงใช้ไม่ได้แน่ ๆ
Version migrations at 4,000-app scale
ส่วนที่ผมว่าน่าสนใจที่สุดใน talk คือตอนที่ Paul เล่าเรื่อง upgrade pain แบบตรงไปตรงมา ตอนที่ Spring Boot ขยับจาก 2 ไป 3 ทั้ง ecosystem ต้องย้าย namespace จาก javax ไป jakarta ทีนี้ก็เจอปัญหา chicken-and-egg app จะ upgrade ไม่ได้ถ้า library ยังไม่ upgrade ส่วน library ก็ upgrade ไม่ได้ถ้าทำแล้ว break app ที่ยังไม่ย้าย
ทางออกของ Netflix คือเขียน custom Gradle transform ที่ไป manipulate bytecode ตอน dependency resolution time ใช้ร่วมกับ OpenRewrite และ Gradle Lint transform ตัวนี้จะ rewrite javax เป็น jakarta ให้อัตโนมัติ library ก็เลยขยับได้ตาม pace ของตัวเองโดยไม่ต้องรอใคร

พอมาถึงการ upgrade จาก Spring Boot 3 ไป 4 ทีมเลือกทางใหม่ไปเลย คราวนี้ใช้ Claude Code รันแบบ headless เป็น batch job ให้ LLM รัน prompt upgrade ต่อเนื่องใน repo แต่ละตัว มีระบบ checkpoint ให้ platform engineer เข้าไป inspect failure และ resume จาก state ที่รู้ว่าดีได้ trade-off ที่น่าสนใจคือ Netflix ตั้งใจเลือก LLM แทน OpenRewrite ที่เป็น AST rule แบบ deterministic เพราะ LLM เขียนถูกกว่าและทนกับ corner case แปลก ๆ ที่ถ้าจะเขียน AST pattern ครอบคลุมหมดต้องใช้เวลานานมาก
Philosophy ที่อยู่เบื้องหลังทั้งหมดนี้คือ รีบฉีกพลาสเตอร์ออก การเลื่อน framework upgrade สร้าง technical debt ที่สุดท้ายจะ block การใช้ library ใหม่ เช่น Spring AI ที่ตอนนี้ทุกคนอยากใช้ การรักษา velocity ก็คือการไม่ปล่อยให้ version gap โตขึ้นเรื่อย ๆ
Protocol standards: GraphQL, gRPC, and REST is dead

Paul ใช้ช่วงสั้น ๆ อธิบายว่า Netflix ใช้ protocol อะไรตรงไหน slide นี้ค่อนข้างชัดและขำดี เพราะมีป้ายหลุมศพ REST อยู่ในรูปด้วย
- GraphQL ใช้ที่ client edge สำหรับการ fetch data แบบยืดหยุ่นที่ client เป็นคน drive DGS framework คือ implementation ฝั่งนี้ คิดในรูปของ data ไม่ใช่ method
- gRPC ใช้แบบเข้มงวดสำหรับ server-to-server backend communication ที่ให้ความสำคัญกับ latency และการ execute method มากกว่าความยืดหยุ่นของ schema คิดในรูปของ method ไม่ใช่ data
- REST ถูก deprecate สำหรับงานพัฒนาหลักใหม่ ๆ ที่ Netflix ไปแล้ว
ผมว่าการตัดสินใจเรื่อง REST น่าสนใจ REST ไม่ได้แย่ แค่พอเรามี federated GraphQL edge ให้ client ใช้ และมี gRPC ให้ service คุยกัน ช่องว่างที่ REST เคยเหมาะที่สุดก็แทบหายไป service ใหม่เลยข้าม REST ไปเลย
Garbage Collection: Generational ZGC
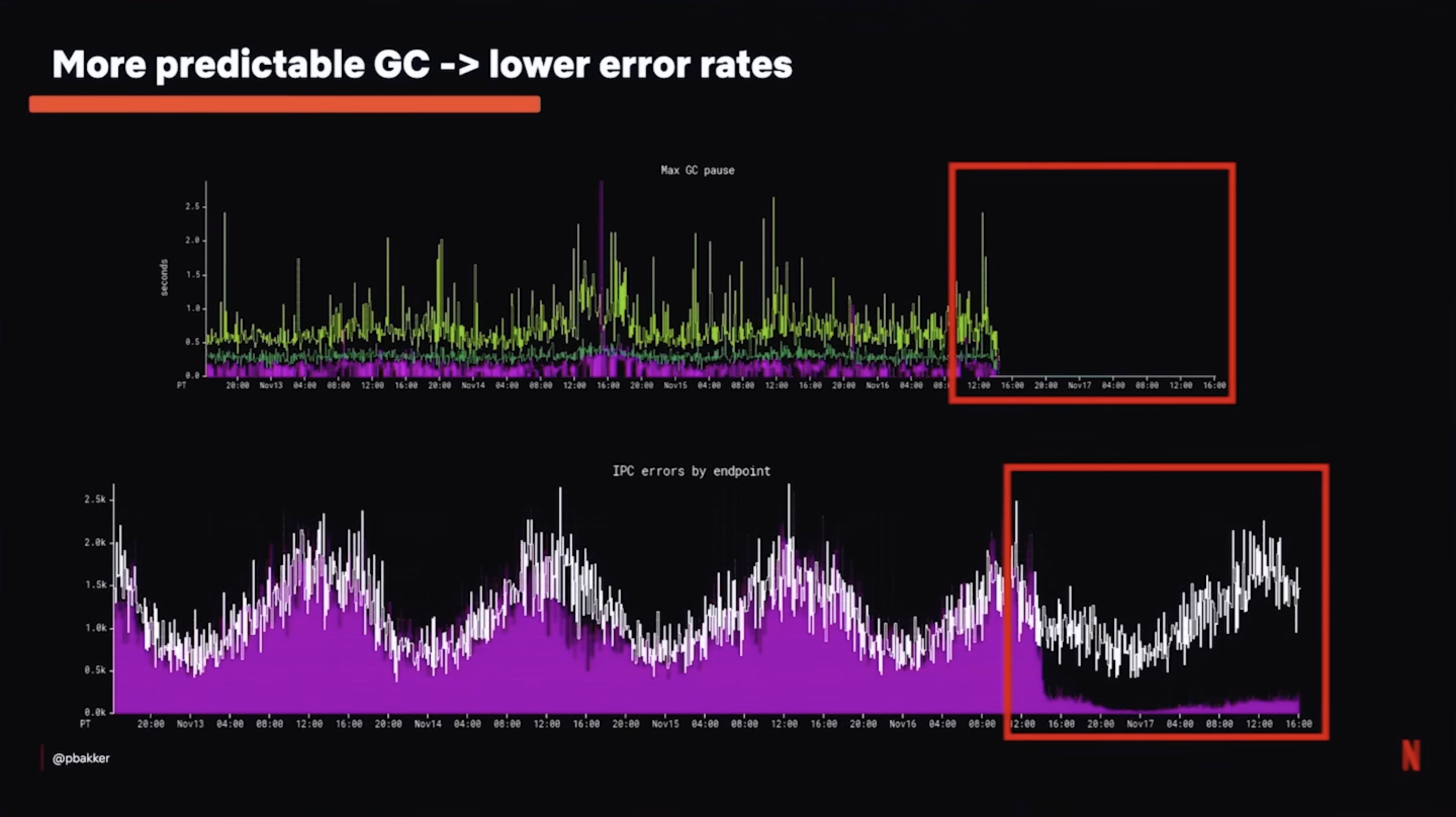
G1GC เคยทำให้ service ของ Netflix มี stop the world pause นานถึง 1.5 วินาที ฟังดูพอรับได้นะครับจนกว่าจะนึกออกว่า Netflix ตั้ง IPC timeout แบบ aggressive ถ้า service pause 1.5 วิ upstream caller จะ give up ทันที แล้ว retry ทีนี้ cluster ทั้งคลัสเตอร์โดน retry storm พอดี pause เดียวกลายเป็น incident ที่ fan-out ไปทั้งระบบ
พอเปลี่ยนมาใช้ Generational ZGC pause หายไปเลย trade-off คือ ZGC กิน baseline CPU มากกว่าสำหรับ background collection แต่การเอา timeout error และ retry traffic ออกไปกลับช่วยลด load โดยรวมของ cluster และลด functional latency ในภาพจะเห็นชัดว่า max GC pause ลดลง และ IPC error per endpoint ก็ลดตามกัน
ปีนี้ Generational ZGC เป็น default GC ของ Netflix microservice ไปแล้ว ถือเป็นการ endorse ที่แรงมาก ถ้ารู้ว่าทีม platform ใหญ่ ๆ มักจะ conservative กับการ switch runtime แค่ไหน
Virtual Threads on JDK 25
Netflix เคยลอง virtual thread ตั้งแต่ JDK 21 แล้วต้อง rollback เพราะเจอ thread-pinning deadlock บาง operation ที่เป็น native หรือ synchronized จะ pin carrier thread ไว้ พอ load สูง application ก็ deadlock ไปเลย
ปัญหา pinning ถูกแก้ใน JDK 25 ตอนนี้ Netflix ใช้วิธี inject virtual thread ที่ framework level อัตโนมัติ ทั้งใน Tomcat connector, thread pool ใน starter และอีกหลายจุด developer ได้ประโยชน์จาก concurrency scaling แบบไม่ต้อง opt-in หรือแก้ code ด้วยซ้ำ
แต่มีรายละเอียดที่คนไม่ค่อยพูดถึงคือเรื่อง context propagation ครับ StructuredTaskScope ไม่ copy ThreadLocal value ไปให้ virtual thread ที่ fork ใหม่ และ ThreadLocal เป็นที่ ๆ tracing, security context, observability metadata อาศัยอยู่ ของใหม่อย่าง ScopedValues ก็ยังไม่มี framework รองรับครอบคลุม
ที่ Netflix เขาแก้ด้วยการ inject custom ThreadFactory เข้าไปใน concurrency scope เพื่อเรียก Micrometer context propagation เองเวลา virtual thread ถูกสร้าง เป็น fix แบบที่จะรู้ว่าต้องทำก็ต่อเมื่อรันบน production แล้วเห็น trace หายไปเฉย ๆ ใครกำลัง rollout virtual thread ใน stack ตัวเอง ผมว่าจำเรื่องนี้ไว้ก็ดี
Newer Java is replacing the role reactive used to play
เรื่องนี้ไม่มี slide ใน talk ปี 2026 แต่ผมอยากดึงออกมาเพราะมันเชื่อมโยงเรื่อง virtual thread เข้ากับ trend ใหญ่กว่าใน Java world ใน talk ปีที่แล้ว Netflix พูดถึง RxJava และ WebFlux ในฐานะ experiment ที่ไม่เวิร์กในบริบทของพวกเขา ในแง่ทฤษฎีมันทรงพลัง แต่ความซับซ้อนของการ debug และ cognitive overhead ไม่คุ้มกับ scale ของทีม ทิศทางที่วางไว้ตอนนั้นคือ virtual thread + structured concurrency จะเข้ามาแทนบทบาทที่ reactive เคยทำ
ผ่านมา 1 ปี ทิศทางนี้ก็ดูถูกอย่างน้อยในบริบทของ Netflix พวกเขา standardize บน WebMVC และ imperative model + virtual thread ก็ให้ประโยชน์เรื่อง concurrency ที่เคยผลักให้ทีมไปใช้ reactive ตั้งแต่แรก โดยไม่ต้องเจอ stack trace ที่ทำให้อยากลาออก
ผมอยากเตือนตัวเองด้วยว่าอย่าเหมารวมเรื่องนี้กว้างเกินไป Reactive ไม่ได้ตายในทุกที่ ยังมีระบบที่ semantics ของ backpressure และการ compose stream คือสิ่งที่ต้องการพอดี และ WebFlux ก็คือคำตอบที่ใช่สำหรับระบบเหล่านั้น แต่ pattern ที่กว้างกว่านั้นมีอยู่ คือทีมจำนวนมากเคยเอื้อมหา reactive เพราะ Java ไม่มี concurrency model ที่ดีพอ และ JDK เวอร์ชันใหม่ก็ค่อย ๆ ปิด gap นั้นในที่สุด ถ้าเหตุผลที่เลือก reactive เพราะต้อง handle IO concurrent เยอะ ๆ โดยไม่ block platform thread ตอนนี้ virtual thread ก็ให้สิ่งนั้นได้แล้วโดยไม่ต้องจ่ายค่า cognitive overhead เพิ่ม คุ้มที่จะกลับไปทบทวน assumption นี้ครั้งหน้าที่จะเริ่ม service ใหม่
Gen AI and Agentic Workflows in Java

ส่วนสุดท้ายของ talk พูดถึง Gen AI ซึ่งผมว่าสนุกที่สุดครับ Netflix กำลังขยับจาก chat completion แบบพื้นฐานไปเป็น Agentic Workflow แบบ structured ที่เขียนอยู่ใน Java microservice ของตัวเอง
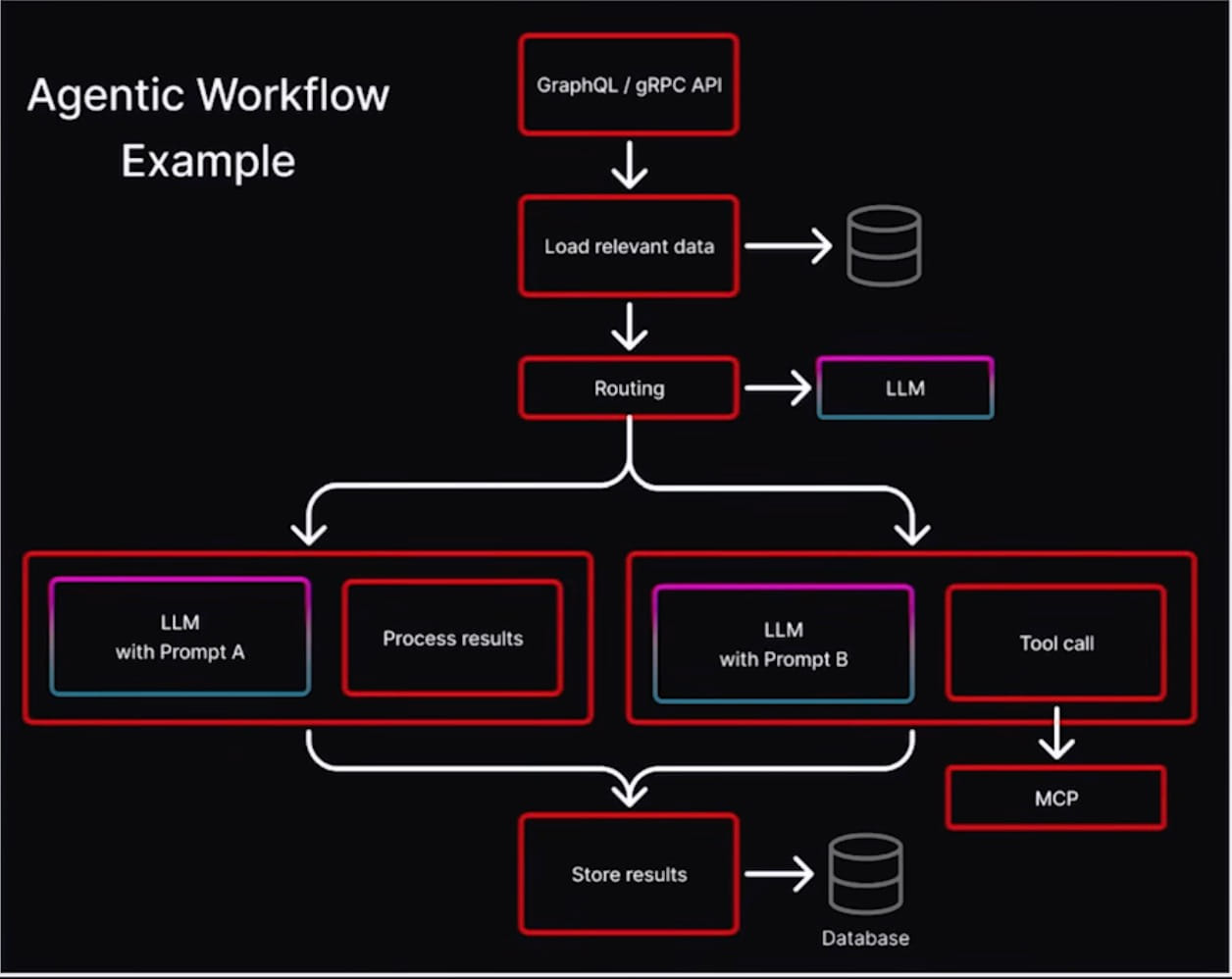
Model คือ application ของเรายังคุม flow หลักแบบ deterministic อยู่ ทั้งการ routing, load data, store result มีเฉพาะบาง node ใน flow เท่านั้นที่จะ call LLM เพื่อให้มันช่วย reason เรื่องเฉพาะ เราไม่ได้มอบการควบคุม program ทั้งตัวให้ model ไป เรามอบแค่บาง decision ให้มัน
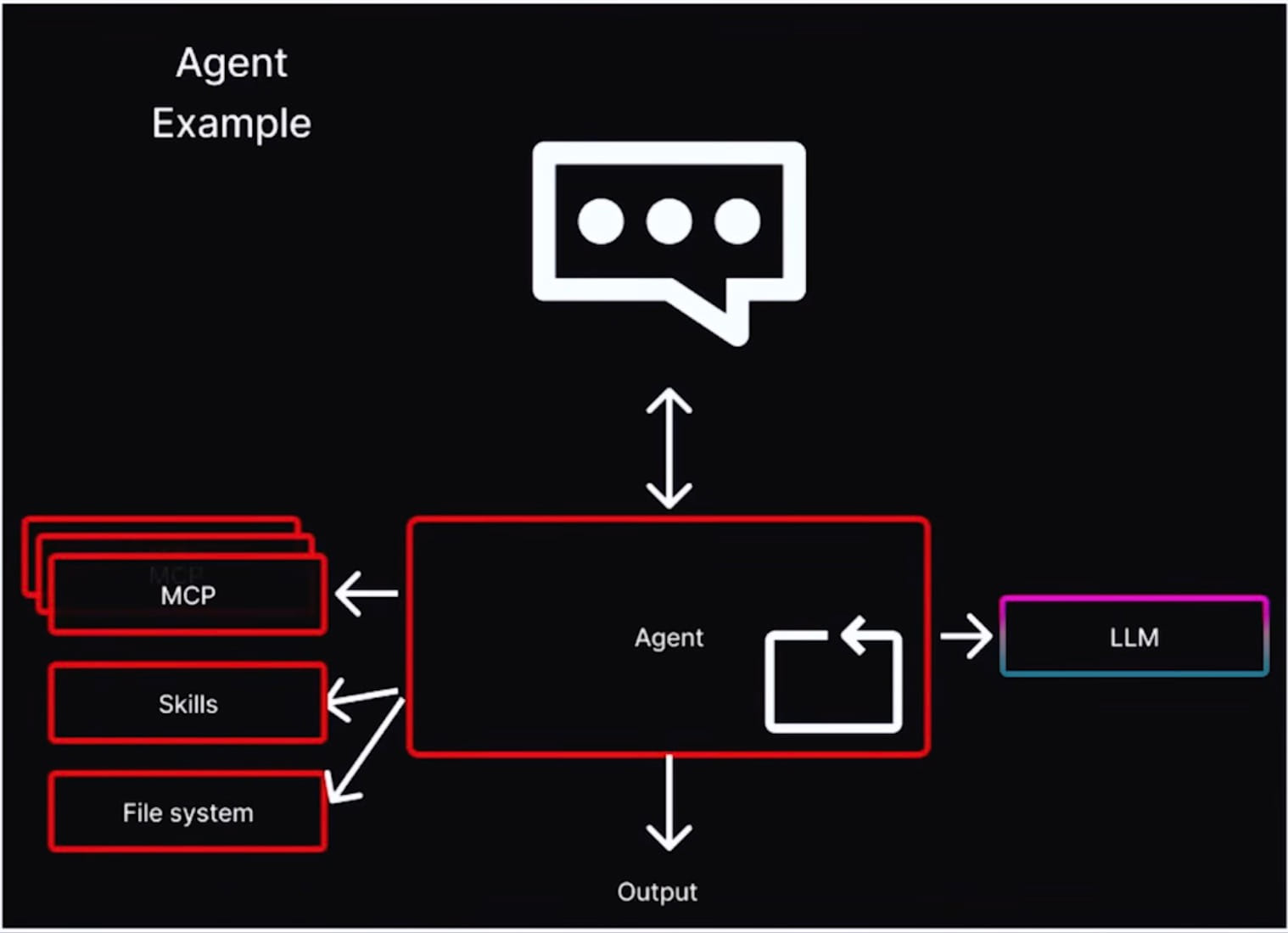
Agent ใน diagram นี้ก็เป็น component ที่เข้าถึง MCP tool, skill, file system และ LLM ได้ โดย wrap อยู่ใน application loop แบบ deterministic หน้าตาของมันเหมือน service design แบบ traditional มากกว่าภาพ chat with your app ที่คนชอบนึกถึง

เรื่องการเลือกภาษา Paul พูดว่า Java ตามทันแล้ว 2 ปีก่อน library Gen AI ส่วนใหญ่มีแค่ใน Python การเลือก Python ตอนนั้นถือว่า pragmatic มาก ปัจจุบัน Spring AI และ LangChain4j ก็ขยับขึ้นมาเทียบเท่า ecosystem ของ Python ได้แล้ว พอรวมกับความเร็วของ JVM และ developer Java ที่มีอยู่จำนวนมหาศาลในบริษัทอย่าง Netflix Java เลยเป็น runtime ที่ดีสำหรับการเอา LLM workflow ขึ้น production
ตัวอย่างที่ Paul ยกมาแล้วผมว่าน่าสนใจมากคือ internal agent ที่ analyze performance ตอน startup ของ Spring application แทนที่จะ dump profiling data ให้ developer ไปอ่านเอง LLM จะอ่าน trace, ดึง source code ของ internal library ที่เกี่ยวข้อง, แล้วเขียน actionable refactoring recommendation ให้เลย นี่คือรูปร่างของ value ที่ Paul อยากชี้ให้เห็น คือการใช้ LLM ปิด gap ระหว่างจุดที่บอกได้แค่ว่ามี data อะไร กับจุดที่บอกได้ว่าต้องไปแก้อะไร
What I take away from this talk
ดู talk จบแล้วมีหลายเรื่องที่ค้างอยู่ในหัว
Default ที่น่าเบื่อแต่เลือกมาดี scale ได้ การที่ Netflix เลือก Spring Boot เป็น paved road และต่อทุกอย่างผ่าน extension point ของ Spring ไม่สร้าง dialect ใหม่ คือเหตุผลที่ app 4,000 ตัวอยู่ด้วยกันได้โดยไม่วุ่น ไม่หวือหวาแต่ผลมัน compound ไปเรื่อย ๆ
ความเร็วของ upgrade เป็น product decision รีบฉีกพลาสเตอร์ออกตั้งแต่เนิ่น ๆ ถ้าปล่อยให้ framework version drift สุดท้ายจะใช้ library ที่ต้องการไม่ได้ Spring AI คือตัวอย่างของปีนี้ batch-upgrade pipeline ที่ใช้ Claude Code ก็เป็นภาพของทิศทางที่ infrastructure work กำลังมุ่งไป
GC choice เป็น reliability lever Generational ZGC คือ win ที่ชัดที่สุดใน talk เอา pause-driven timeout ออก retry load ก็ลด cluster ก็เงียบขึ้น ถ้ายังอยู่บน G1GC ผมว่าลองไป test ดูใน service ของตัวเองได้เลย
Virtual thread พร้อมใช้แล้ว แต่ระวัง plumbing ด้วย context propagation คือจุดที่จะกัดเราแน่ ถ้า tracing และ security context อาศัย ThreadLocal อยู่ ต้อง rollout อย่างระวังและเช็กว่า span หายไปไหม ก่อนจะ celebrate
Java เวอร์ชันใหม่กำลังเข้ามาแทนบทบาทของ reactive virtual thread + structured concurrency ครอบคลุม use case ส่วนใหญ่ที่เคยผลักให้ทีมเลือก WebFlux/RxJava reactive ยังเป็นคำตอบที่ใช่ในบางที่ แต่ถ้าเหตุผลที่เลือกคือต้องการ non-blocking concurrency บน JVM เหตุผลนั้นอ่อนลงเยอะแล้ว
Agentic workflow อยู่ได้ใน Java service การคุม application loop แบบ deterministic และเรียก LLM แค่บาง node มัน operable กว่าการมอบทุกอย่างให้ agent เยอะ และพอมี Spring AI กับ LangChain4j เราก็ไม่ต้องออกจาก JVM เพื่อทำเรื่องนี้แล้ว
Action item ของผมจาก talk นี้: อยากลองมือทำ agentic workflow ด้วย Java (Spring AI, LangChain4j, หรือ ADK Java) แทน Python ดูสักตัว JVM จะกิน memory เยอะกว่า Python ตรงนั้นยอมรับ แต่สำหรับ service ที่รันยาว ๆ บน production throughput และ latency น่าจะดีกว่าในเชิงเทคนิค เรื่องนี้อยู่ใน list side project ที่อยากทำเร็ว ๆ นี้