
Agent Skills คืออะไร?
เมื่อเร็วๆ นี้ได้ดูวิดีโอของ ByteByteAI (ByteByteGo) ชื่อ “What Are Agent Skills Really About?” แล้วหลายอย่างก็ click เข้าที่
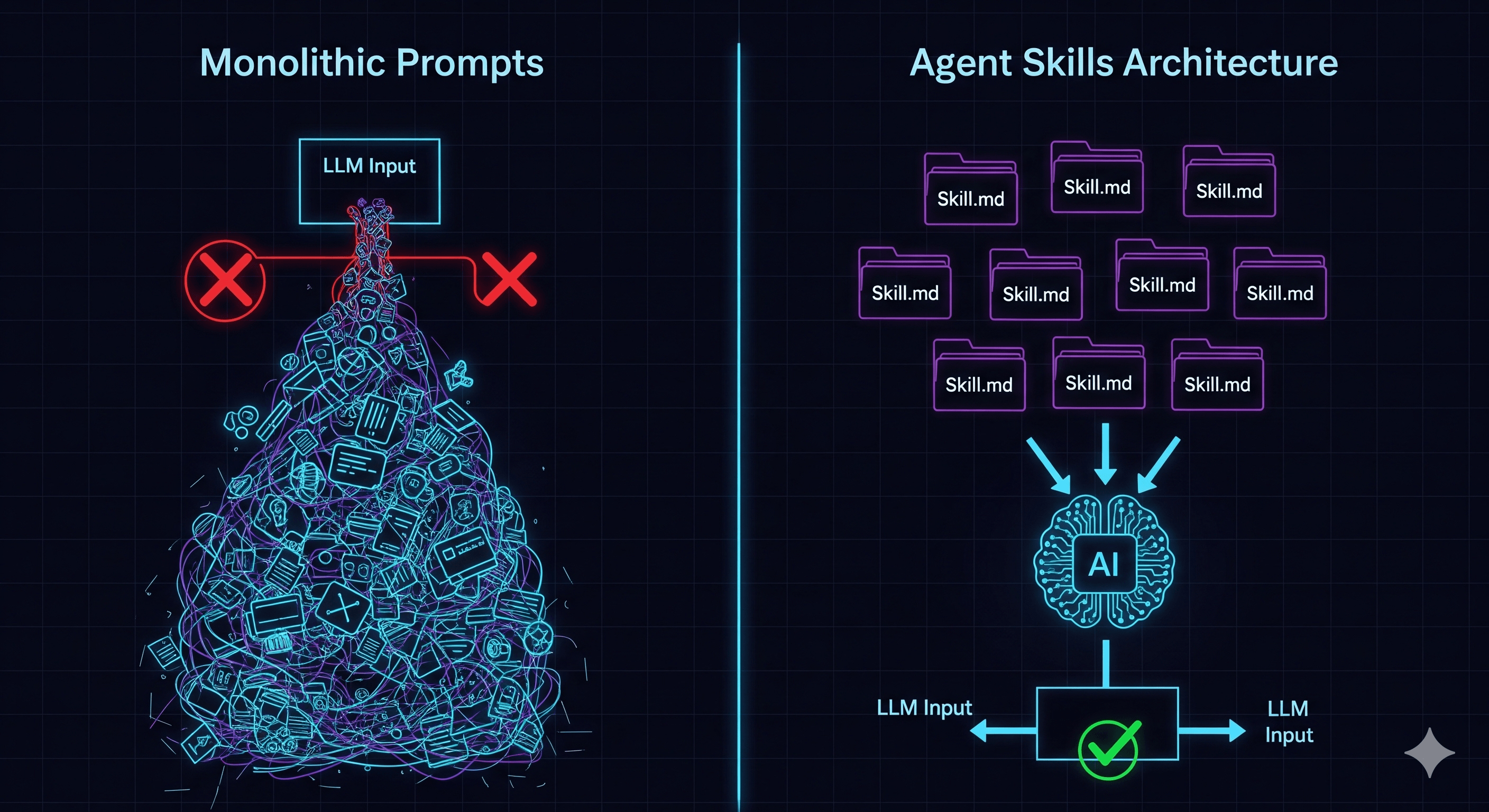
ถ้าเคยลองสร้าง AI agents มา คงเคยชนกับ “Context Wall” เริ่มจาก system prompt ง่ายๆ แล้วก็เพิ่ม rules เพิ่ม function definitions เพิ่ม style guide จู่ๆ prompt ก็ยาว 4,000 tokens model เริ่มลืมครึ่งนึงของ instructions แล้ว API costs ก็พุ่ง
เรามักคิดว่าทางออกคือ “context window ที่ใหญ่ขึ้น” (1M+ tokens) แต่วิดีโอนี้ argue ว่า architecture ต่างหากคือคำตอบ ไม่ใช่ขนาด context
นี่คือสิ่งที่เรียนรู้เรื่อง Agent Skills กับ Progressive Disclosure และทำไมถึงคิดว่านี่คือ paradigm ของ reliable agents ในอนาคต
ปัญหา: กับดัก “Monolithic Prompt”
เรามักปฏิบัติกับ LLMs เหมือน intern สุดวิเศษที่ต้องรู้ ทุกอย่าง ก่อนเริ่มงานวันแรก เรายัด context window ด้วย:
- Tool definition ทุกตัวที่เป็นไปได้
- Brand voice guidelines ทั้งหมด
- Edge case rules 50 กว่าข้อ
- Database schema เต็มๆ
ทำไมถึงล้มเหลว:
- Attention Drift (พิสูจน์แล้ว ไม่ใช่แค่ความรู้สึก): นักวิจัยจาก Stanford เรียกปัญหานี้ว่า “Lost in the Middle” งานวิจัยแสดงให้เห็นว่า LLMs ทำงานได้ดีที่สุดกับข้อมูลที่อยู่ ต้น และ ท้าย ของ context window แต่ accuracy ลดลง กว่า 30% สำหรับข้อมูลที่อยู่ตรงกลาง Instructions มากขึ้นไม่ได้แปลว่า understand ดีขึ้น — มันมักหมายถึง แย่ลง
- Cost & Latency: การยัด context window ด้วย “dead code” (instructions ที่ไม่ต้องใช้ใน task ปัจจุบัน) ทั้งแพงและทำให้ generation ช้าลง
- Fragility: การแก้ “Email Style Guide” อาจทำให้ “SQL Generation” logic พังโดยไม่ตั้งใจ เพราะ share prompt space เดียวกัน
flowchart LR
subgraph without["Without Skills"]
direction TB
wp["Prompt
─────────────
System Prompt
Tool #1 definition
Tool #2 definition
Tool #3 definition
Instruction #1
Instruction #2
Instruction #3
...
User Prompt"] --> wllm[LLM]
end
subgraph with["With Skills"]
direction TB
cp["Prompt
─────────────
System Prompt
Skills Index
User Prompt"] --> cllm[LLM]
cllm -->|"load_skill"| skills
skills["Skills
─────────────
Skill 1 · Skill 2 · ... · Skill K
(Tools + Instructions each)"] -.->|"on demand"| cp
end
ทางออก: Progressive Disclosure
Core idea นั้นเรียบง่ายแต่ทรงพลัง: อย่าให้ manual ทั้งเล่มกับ agent — ให้แค่สารบัญ
แทนที่จะ load ทุก instruction ตั้งแต่แรก agent เริ่มต้นด้วย Skill Index เล็กๆ ซึ่งเป็นแค่ list ของชื่อกับ description สั้นๆ หนึ่งบรรทัด (เช่น “Spreadsheet Audit”, “Email Drafter”, “SQL Query”)
เมื่อ task เข้ามา agent ดู index แล้วคิดว่า “ฉันไม่รู้วิธี audit spreadsheet แต่เห็น skill ชื่อ spreadsheet_audit อยู่ โหลดมันมาดีกว่า”
จากนั้น เท่านั้น ระบบถึงจะ inject instructions ที่หนักเข้ามา
Anatomy of a Skill
วิดีโอนิยาม “Skill” ไม่ใช่แค่ concept ลอยๆ แต่เป็น folder structure ที่จับต้องได้ ซึ่ง appeal กับสมอง backend มาก — มันคือ modularity ที่ apply กับ prompts
Skill หนึ่งประกอบด้วย:
SKILL.md: “Prompt” จริงๆ สำหรับ task นั้น มี rules, guardrails, และ “How-To” สำหรับ domain นั้นโดยเฉพาะ- Scripts (เช่น
audit.py): ส่วนนี้สำคัญมาก วิดีโอเน้นว่าสำหรับ deterministic logic (คำนวณ, parsing, validation) ไม่ควรพึ่ง LLM ควรใช้ code LLM แค่เรียก script - Resources: Static files, templates, หรือ schemas (เช่น JSON template สำหรับ output)
Aside: ตอนนี้มันเป็น open standard แล้ว ในเดือนธันวาคม 2025 Anthropic ปล่อย Agent Skills specification เป็น open format ไม่ใช่แค่ของ Claude อีกต่อไป OpenAI Codex, GitHub Copilot, VS Code, Cursor, และ platform อื่นอีก 20+ ได้ adopt แล้ว Skill ที่เขียนครั้งเดียวใช้ได้ข้าม agents Spec นั้นเล็กมาก — อ่านจบได้ภายในไม่กี่นาที
Visualizing the Flow
ลอง map flow ออกมาเพื่อให้เห็นภาพว่า context เปลี่ยนแปลงอย่างไรแบบ dynamic มันคือ “Lazy Loading” สำหรับ prompts
sequenceDiagram
participant User
participant Agent (Runtime)
participant LLM
participant SkillStore
Note over LLM: Context: [Tiny Skill Index only]
User->>Agent: "Audit this spreadsheet for me"
Agent->>LLM: Forwards request
LLM->>Agent: "I need to load 'Spreadsheet Audit' skill"
Agent->>SkillStore: Fetch skill.md + scripts
SkillStore->>Agent: Returns artifacts
Note over Agent: Appends skill.md to Context
Note over LLM: Context: [Index + FULL AUDIT RULES]
Agent->>LLM: "Skill loaded. Proceed."
LLM->>Agent: "Run audit.py on the file"
Agent->>Agent: Executes Python Script (Deterministic)
Agent->>LLM: Returns structured JSON result
LLM->>User: "Here is the audit report..."
ความเห็นส่วนตัว: ทำไมมันถึงสำคัญ
1. ก้าวจาก “Prompt Engineering” สู่ “Software Engineering”
เรากำลังก้าวจาก “Prompt Engineering” ในฐานะศาสตร์ลึกลับ ไปสู่ “Software Engineering with AI components” การแยก Index (Interface) ออกจาก Skill.md (Implementation) คือวิธีเดียวกับที่เราเขียน code ที่ดี
มัน enable หลักการ S.O.L.I.D. สำหรับ agents:
- Single Responsibility:
spreadsheet_auditskill ไม่จำเป็นต้องสนใจemail_writerskill - Open/Closed: เพิ่ม skill ใหม่ใน index ได้โดยไม่ต้อง rewrite core system prompt
2. Code > LLM สำหรับ Logic
วิดีโอเน้นว่า skill มี scripts รวมอยู่ด้วย นี่คือการ validate แนวทาง “Hybrid” อย่าให้ LLM คำนวณ sum ของ column หรือ parse complex PDF ให้มันเขียน/run script ทำแทน Skill encapsulate ทั้ง ความเข้าใจ (LLM) และ การทำงาน (Code) ไว้ด้วยกัน
3. Portable Intelligence
ถ้า structure skills เป็น folders (Filesystem-based) มันก็ portable ได้ทันที แชร์ “GitHub Issue Triage” skill ข้าม agents หรือ projects ต่างๆ ได้ ตอนนี้มันเป็น open standard แล้ว ไม่ใช่แค่ hypothetical — มันคือวิธีที่ ecosystem ทำงานจริงๆ
flowchart BT
skill["Skill X
(SKILL.md + Scripts + Resources)"]
ta["Team A"] --> skill
tb["Team B"] --> skill
e1["Claude Code"] --> skill
e2["GitHub Copilot"] --> skill
e3["VS Code"] --> skill
e4["Cursor"] --> skill
ลองทำเอง: สร้าง Skill แรกใน 5 นาที
ทฤษฎีพอแล้ว นี่คือ minimum ที่ต้องใช้สร้าง working skill ลองได้กับ Claude Code, GitHub Copilot, หรือ agent ตัวไหนก็ได้ที่ support standard นี้
Step 1: สร้าง folder
my-project/
└── .skills/
└── code-reviewer/
├── SKILL.md
└── scripts/
└── check_complexity.pyStep 2: เขียน SKILL.md
---
name: code-reviewer
description: Reviews pull request diffs for code smells, complexity, and naming issues.
---
## Instructions
You are a code reviewer. When the user asks you to review code or a PR diff:
1. First, run `scripts/check_complexity.py` on the changed files to get cyclomatic complexity scores.
2. Flag any function with complexity > 10.
3. Check for: unclear variable names, functions longer than 40 lines, missing error handling.
4. Output a markdown table with: File, Function, Issue, Severity (Low/Medium/High).
## Tone
Be direct but constructive. Suggest fixes, don't just complain.Step 3: เพิ่ม helper script
# scripts/check_complexity.py
import ast
import sys
def get_complexity(filepath):
"""Count branches (if/for/while/except) per function as a simple complexity proxy."""
with open(filepath) as f:
tree = ast.parse(f.read())
results = []
for node in ast.walk(tree):
if isinstance(node, (ast.FunctionDef, ast.AsyncFunctionDef)):
branches = sum(1 for child in ast.walk(node)
if isinstance(child, (ast.If, ast.For, ast.While, ast.ExceptHandler)))
results.append({"function": node.name, "line": node.lineno, "complexity": branches + 1})
return results
if __name__ == "__main__":
for filepath in sys.argv[1:]:
for r in get_complexity(filepath):
print(f"{filepath}:{r['line']} - {r['function']}() complexity={r['complexity']}")แค่นี้เอง สามไฟล์ Agent เห็นแค่ name กับ description ตอน startup (~20 tokens) เมื่อใครบอก “review PR นี้หน่อย” agent จะ load SKILL.md เต็มๆ แล้วก็รู้เลยว่าต้องทำอะไร รวมถึงการ run code จริงสำหรับส่วนที่ต้องการ determinism
Context เปลี่ยนอย่างไรในแต่ละ Stage
| Stage | สิ่งที่อยู่ใน context | Token cost |
|---|---|---|
| Startup | "code-reviewer: Reviews pull request diffs..." | ~20 tokens |
| Skill activated | Full SKILL.md instructions | ~200 tokens |
| Script result loaded | Complexity report output | ~100 tokens |
เทียบกับการยัด instructions เดียวกันใน system prompt ถาวร: จะต้องจ่าย ~200 tokens ใน ทุก request แม้แต่ตอนที่ user แค่อยากคุยทั่วไป
เมื่อไหร่ที่ไม่ต้องใช้
พูดตามตรง — ไม่ใช่ทุก agent ที่ต้องการ skills ถ้า agent ทำ แค่เรื่องเดียว กับ 3-5 tools ใช้ system prompt เดียวก็พอ Monolithic approach เริ่มพังเมื่อ:
- มี 10+ capabilities ที่แตกต่างกัน ใน agent ตัวเดียว
- Task ต่างกันต้องการ instructions ที่ขัดแย้งกัน (formal email tone vs. casual chat)
- Prompt ยาวเกิน 2,000 tokens แล้วยังโตขึ้นเรื่อยๆ
ถ้าไม่ตรงข้อไหนเลย ก็ keep it simple Skills มีไว้สำหรับเมื่อ simplicity หยุด scale
สรุป
”Agent Skills” pattern ไม่ใช่ technology ใหม่ — มันคือ architectural pattern มัน acknowledge ว่า LLMs เป็น reasoning engines ที่ทรงพลังแต่เป็น databases ที่แย่ ด้วยการใช้ Progressive Disclosure เราทำให้ reasoning engine focused, เร็ว, และแม่นยำ
ถ้ากำลังสร้าง agents อยู่แล้วชนกับ context wall ลองดึง capability สักตัวจาก system prompt ออกมาเป็น skill folder สัปดาห์นี้ จะรู้สึกถึงความแตกต่างเรื่อง focus กับ maintainability ทันที
Give more, learn more. Be better each day.
References: